[論文レビュー] Finding Inductive Loop Invariants using Large Language Models
本論文は、 大規模言語モデル(LLMs)を用いてCプログラムの帰納的ループ不変量を生成し、LLM出力と記号検証ツールを組み合わせてHoare三重を検証し、記号ベースのベースラインより多くの場合で検証性能が向上することを示す。
Loop invariants are fundamental to reasoning about programs with loops. They establish properties about a given loop's behavior. When they additionally are inductive, they become useful for the task of formal verification that seeks to establish strong mathematical guarantees about program's runtime behavior. The inductiveness ensures that the invariants can be checked locally without consulting the entire program, thus are indispensable artifacts in a formal proof of correctness. Finding inductive loop invariants is an undecidable problem, and despite a long history of research towards practical solutions, it remains far from a solved problem. This paper investigates the capabilities of the Large Language Models (LLMs) in offering a new solution towards this old, yet important problem. To that end, we first curate a dataset of verification problems on programs with loops. Next, we design a prompt for exploiting LLMs, obtaining inductive loop invariants, that are checked for correctness using sound symbolic tools. Finally, we explore the effectiveness of using an efficient combination of a symbolic tool and an LLM on our dataset and compare it against a purely symbolic baseline. Our results demonstrate that LLMs can help improve the state-of-the-art in automated program verification.
研究の動機と目的
- LLMsによる不変量生成を研究するために、ループを含むCプログラムの検証問題のデータセットを作成する。
- ループ不変量を生成するようLLMsに促すツールチェーンを開発し、それを記号検証器で検証する。
- データセット上で、異なるLLMとハイブリッドなLLM-記号アプローチを、記号ベースラインと比較して評価する。
- LLMの不正確さを許容しつつ帰納性を保証する修復対応を備えたパイプラインを提案・評価する。
提案手法
- LLM(L)とオラクル/記号検証器(O)を備えた二成分ツールチェーンを構築する。
- プロンプト Mと対象プログラム P を用いて、Lを介して候補不変量 I を生成する。
- Pに対して I を A(P,I) として注釈付けし、Oで帰納性を検証する。
- Loopyを適用する: 完了を横断して I を蓄積し、次に Houdini を用いて帰納的部分集合を抽出する、あるいは Repair で I を改善する。
- Houdini は非帰納的な候補や構文的に無効な候補を剪定し、帰納的な部分集合を探索する。
- Repair は反復的に L にエラー情報を基に不変量を修復させ、再度 O で検証する。
実験結果
リサーチクエスチョン
- RQ1RQ1 LLM はCプログラムに対して正しいループ不変量のセットをどのくらいの頻度で生成できるか?
- RQ2RQ2 LLM はCプログラムを検証するために必要な正しい不変量のセットの要素をどのくらいの頻度で生成できるか?
- RQ3RQ3 異なる基盤モデルは帰納的不変量を見つける能力においてどのように比較されるか?
- RQ4RQ4 オラクルからのエラーメッセージを用いて LLM は不正確な不変量をどのくらいの頻度で修正できるか?
- RQ5RQ5 LLM が正しい不変量を生成できないプログラムの特徴は何か?
- RQ6RQ6 Loopy の性能は最先端の記号検証器と比較してどうか?
主な発見
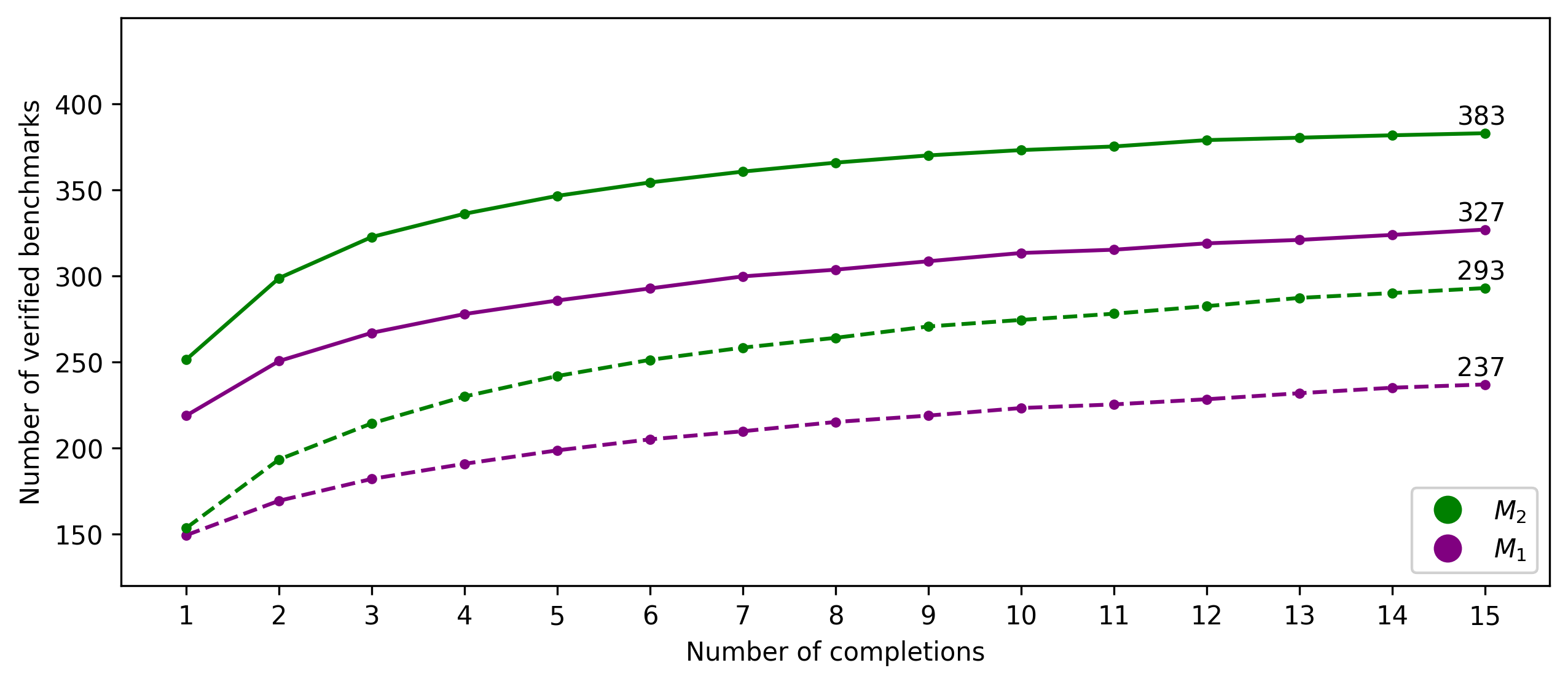
- Loopy の成功は完了数が増えるにつれて高まるが、約8回の完了を超えると律速が小さくなる。
- プロンプトにニュース(M2)を含めると、単純なプロンプト(M1)に比べて成功率が約23%向上する。
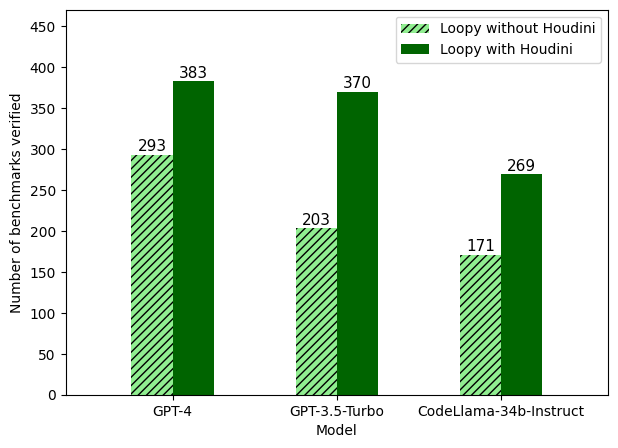
- Houdini は LLM で生成された部分的不変量を活用することで性能を大幅に向上させる。
- GPT-4 は一般に他の LLM より優れているが、Houdini は他モデルの追いつきを助ける;複数の LLM を使用することが有益である可能性。
- Repair は検証到達範囲をさらに広げ、報告設定では Houdini 単独の 383 件に対し 398 件の解決を達成した。
- 記号ベースライン Ultimate と比較すると、Loopy は Ultimate が解けないいくつかのベンチマークを解決する一方、全体としては Ultimate がより多くを解く(469 ベンチマーク中 430 対 398)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。