[論文レビュー] Finding Neurons in a Haystack: Case Studies with Sparse Probing
本論文は、LLMの活性化において人間が解釈可能な特徴をエンコードする個々のニューロンまたは疎なニューロン部分集合を特定するためのスパースプロービングを導入し、表現がモデル規模の拡大とともにどのように進化するかを分析し、複数のモデルと特徴に渡るケーススタディを提示する。
Despite rapid adoption and deployment of large language models (LLMs), the internal computations of these models remain opaque and poorly understood. In this work, we seek to understand how high-level human-interpretable features are represented within the internal neuron activations of LLMs. We train $k$-sparse linear classifiers (probes) on these internal activations to predict the presence of features in the input; by varying the value of $k$ we study the sparsity of learned representations and how this varies with model scale. With $k=1$, we localize individual neurons which are highly relevant for a particular feature, and perform a number of case studies to illustrate general properties of LLMs. In particular, we show that early layers make use of sparse combinations of neurons to represent many features in superposition, that middle layers have seemingly dedicated neurons to represent higher-level contextual features, and that increasing scale causes representational sparsity to increase on average, but there are multiple types of scaling dynamics. In all, we probe for over 100 unique features comprising 10 different categories in 7 different models spanning 70 million to 6.9 billion parameters.
研究の動機と目的
- LLMsの内部ニューロン活性化において、高レベルで人間が解釈できる特徴がどのように表現されているかを調査する。
- 特定の特徴に関与するニューロンを局在化するため、k-sparseプローブを開発・適用する。
- モデル規模と層の変化とともに特徴表現がどのように変化するかを調べ、スパーシティの動態を明らかにする。
- 表現における重ね合わせ、モノセマンティ、および規模が表現に及ぼす影響を示すケーススタディを提供する。
提案手法
- 入力特徴を予測するために、内部活性化上でk-sparse線形分類器(プローブ)を訓練する。
- 適応的閾値処理と最適なスパースプロービング(OSP)を用いて、予測力の高い上位kニューロンを選択する。
- プロービング法を比較し、保持データ以外のデータで精度、再現率、F1、MCCを用いて評価する。
- トランスフォーマーのMLP層(パラメータの約2/3)での活性化を分析し、特徴関連ニューロンを特定する。
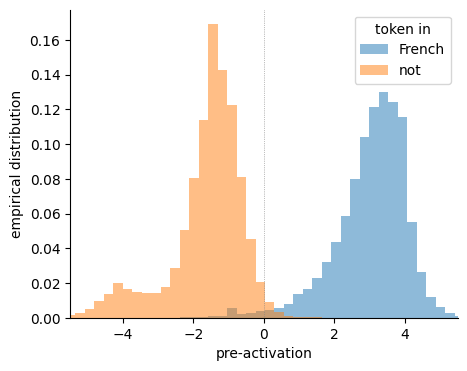
実験結果
リサーチクエスチョン
- RQ1高レベルの特徴が、LLMにおいて単一ニューロンによって表現されるのか、それとも疎な組み合わせ(重ね合わせ)によって表現されるのか、その程度はどれくらいか?
- RQ2表現のスパース性と特徴対応ニューロンの位置は、モデルサイズと層の変化とともにどのように変化するか?
- RQ3中間層のニューロンは高レベルの文脈的特徴に対してモノセマンティである傾向がある一方、初期層はより多義的な重ね合わせを示すのか?
- RQ4多様な特徴タイプにわたって、疎なプローブが特徴ニューロン対を特定する際の信頼性と解釈性はどの程度か?
- RQ5ニューロン表現をプローブする際の方法論的考慮事項と潜在的な混乱要因は何か?
主な発見
- 多くの特徴で重ね合わせに関与するモノセマンティニューロンとポリセマンティックニューロンの双方が存在する。
- 初期層は多くの特徴を重ね合わせで表現する疎なニューロンの組み合わせを示し、中間層は高レベルの文脈的特徴に対して一見専用のニューロンを保持している。
- モデル規模が拡大すると、平均的な表現のスパース性が増加する一方、特徴タイプごとに異なるスケーリングダイナミクスを示す。
- モデルサイズを増やすと、いくつかの特徴に対してより細粒度な表現が得られる一方で、特徴の分割や専用回路によって他の特徴ではスパース性が低下することがある。
- 本研究は、70Mから6.9Bパラメータにわたる7モデルで100を超える特徴を探索し、スパース表現の存在とダイナミクスを実証している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。