[論文レビュー] Fine-grained Hallucination Detection and Editing for Language Models
本論文はLM幻覚の細かな分類法を提案し、検出と編集のためのFavaを提示し、約1,000件の人間判断を含むLM評価用ベンチマークFavaBenchを導入する。Favaは事実誤差の検出と編集において、ベースラインを上回ることを示している。
Large language models (LMs) are prone to generate factual errors, which are often called hallucinations. In this paper, we introduce a comprehensive taxonomy of hallucinations and argue that hallucinations manifest in diverse forms, each requiring varying degrees of careful assessments to verify factuality. We propose a novel task of automatic fine-grained hallucination detection and construct a new evaluation benchmark, FavaBench, that includes about one thousand fine-grained human judgments on three LM outputs across various domains. Our analysis reveals that ChatGPT and Llama2-Chat (70B, 7B) exhibit diverse types of hallucinations in the majority of their outputs in information-seeking scenarios. We train FAVA, a retrieval-augmented LM by carefully creating synthetic data to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT and GPT-4 on fine-grained hallucination detection, and edits suggested by FAVA improve the factuality of LM-generated text.
研究の動機と目的
- 情報探索タスクのための言語モデル出力における幻覚の細かな分類法を開発する。
- 複数のモデルとドメインにわたるスパンレベルの注釈を持つベンチマーク(FavaBench)を作成する。
- LM出力の事実誤りを検出・訂正するリTRieval-augmented editing model(Fava)を構築する。
- 細かな検出と編集が強力なベースラインより事実性を向上させることを実証する。
提案手法
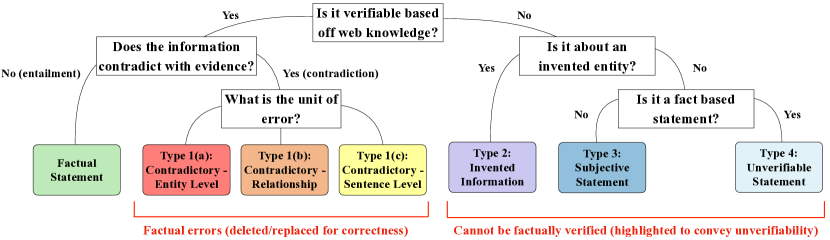
- 六種の細かな幻覚分類と二つのタスク評価を提案する:検出(spanレベルのエラータイプ識別)と編集(spanレベルの訂正)。
- 多様なプロンプトとドメインに対して spanレベルで注釈付けされた約1,000件のモデル出力を用いたFavaBenchを構築する。
- retrieval-augmented editing modelとしてFavaを訓練する。取得文書を用いてLM出力の事実誤りを識別しタグ付けする。
- シード文の生成、分類法を用いたターゲットエラーの挿入、後処理という三段階のパイプラインで高品質な合成トレーニングデータを生成する。
- 合成データ上で編集LM(Fava)を初期化・訓練し、関連文書を文脈として選択するリトリーバルモジュール(トップ-5)を使用する。
- 細かな検出(F1)と編集(FActScoreに基づく向上)において、FavaをChatGPT、GPT-4、リトリーバー拡張ベースラインと比較評価する。

実験結果
リサーチクエスチョン
- RQ1情報探索タスクにおけるLM出力の幻覚の異なる細かなカテゴリは何か?
- RQ2retrieval-augmented editing modelは、 spanレベルの事実誤りをより効果的に検出・訂正できるのか、強力なベースラインと比べて?
- RQ3シSyntheticデータ生成パイプラインは、細かな幻覚検出・編集モデルを訓練するのに十分か?
- RQ4取得品質と文脈は事実性の編集性能にどのように影響するか?
- RQ5異なるモデルとドメインを横断した幻覚タイプの普及率と分布はどうなるか?
主な発見
- 評価されたすべてのモデルは、情報探索プロンプト全般で出力の大半に幻覚を持つ。
- エンティティの誤りが最も頻繁であるが、創出的・検証不能な誤りも一般的であり、細かな検出の必要性を浮き彫りにしている。
- Favaは細かな幻覚検出と編集の有効性でChatGPT、GPT-4、リトリーバー拡張ベースラインを上回り、FActScoreで実質的な向上を示す。
- トップ5文書を用いたリトリーバル拡張編集は、1つの文書や取得なしより事実性を改善する。
- より大規模な合成トレーニングデータは検出性能を向上させ、より良い取得順序とエンティティベースのプロンプティングは編集の効果をさらに高める。
- 人間による評価は、Favaの検出と編集能力が強力なベースラインに対して意味ある事実性の改善を提供することを確認。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。