[論文レビュー] FLAVA: A Foundational Language And Vision Alignment Model
FLAVA は、単一のトランスフォーマーベースのモデルで、単一モーダルおよびマルチモーダルデータで事前学習され、視覚、言語、およびマルチモーダル推論タスクで優れた性能を発揮し、35 タスクにわたって評価される。
State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal (with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising direction would be to use a single holistic universal model, as a "foundation", that targets all modalities at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate impressive performance on a wide range of 35 tasks spanning these target modalities.
研究の動機と目的
- 視覚、言語、マルチモーダルタスクを同時に扱える単一の基盤モデルの必要性を動機づける。
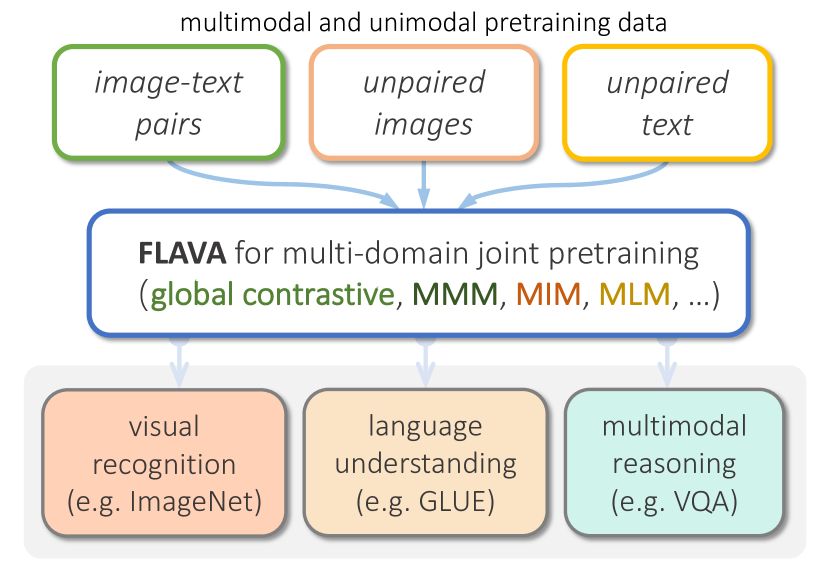
- 単一モードとマルチモードの表現を統合する統一FLAVAアーキテクチャを提案する。
- 対照学習、 MMM、 ITM、 MLM、 MIM を組み合わせたジョイント事前学習目的を開発する。
- 公開データを用いた広範な下流タスクの有効性をFLAVAで示す。
- 単一モード事前学習データがマルチモーダルおよび言語能力を向上させることを示す。
提案手法
- アーキテクチャは3つのトランスフォーマーを組み合わせる:単一モードの視覚には画像エンコーダ(ViT)、単一モードの言語にはテキストエンコーダ(ViTベース)、統合表現のためのマルチモーダルエンコーダ。
- マルチモーダル事前学習はグローバル対照損失、マスクドマルチモーダルモデリング(MMM)、および画像-テキストマッチング(ITM)を使用する。
- 単一モード事前学習には画像のマスクドイメージモデリング(MIM)とテキストのマスクドランゲージモデリング(MLM)を含み、任意の単一モード初期化を伴う。
- 単一モードとマルチモーダルの訓練を結合し、データタイプ(PMD, ImageNet-1K, CCNews, BookCorpus)をラウンドロビン方式で交互にサンプリングする。
- データソースは公開されている70Mの画像-テキストペア(PMD)に加え、単一モードデータセット(ImageNet-1K、CCNews、BookCorpus)からなる。
- モデルは共有トランクを用い、視覚、NLP、およびマルチモーダルタスク用のタスク固有ヘッドを適用する。
実験結果
リサーチクエスチョン
- RQ1単一の基盤モデルは、単一モードおよびマルチモーダルデータの両方から視覚、言語、マルチモーダル推論の強力な表現を学習できるか?
- RQ2異なる事前学習目的(対照学習、MMM、ITM、MLM、MIM)は、単一モードおよびマルチモーダルの性能にどのように寄与するか?
- RQ3対照学習のための単一モード事前学習とGPU全体でのグローバルバックプロパゲーションからどのような利得が生じるか?
- RQ4視覚、NLP、マルチモーダル領域にまたがる35タスクのベンチマークでFLAVAはどのように機能するか?
- RQ5FLAVAはより大規模な私的データセットで訓練された最先端のマルチモーダルモデルと比較してどうか?
主な発見
- FLAVAは視覚、言語、マルチモーダルタスク全体で堅調な平均性能を達成し、いくつかのアブレーションを上回る。
- MMMとITM目的を導入することで、対照学習のみの事前学習を超えるマルチモーダル結果を得る。
- 単一モード初期化を伴う単一モードとマルチモーダルの共同事前学習はNLP性能を向上させ、事前学習済みの視覚エンコーダと言語エンコーダを使用すると顕著な向上がある。
- 公開データ(70M PMDペアと単一モードデータ)で訓練されたFLAVAは、はるかに大規模な私的データセットで訓練されたモデルと競争力がある。
- 対照的目的のグローバルバックプロパゲーションは複数のモダリティにわたるマクロ平均の利得をもたらす。
- FLAVAはVQA、SNLI-VE、Hateful Memes、GLUE風の言語タスクなどの広範なタスク群で強力な結果を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。