[論文レビュー] Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Florence-2は、FLD-5Bで訓練された統一的でプロンプトベースのビジョンファウンデーションモデルを提示し、キャプショニング、検出、グラウンディング、セグメンテーションなど多様なタスクをゼロショットおよびファインチューニング機能と共に実行します。さらに、広範なデータエンジンと seq2seq アーキテクチャを導入し、ビジョンタスクを単一のモデルに統合します。
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
研究の動機と目的
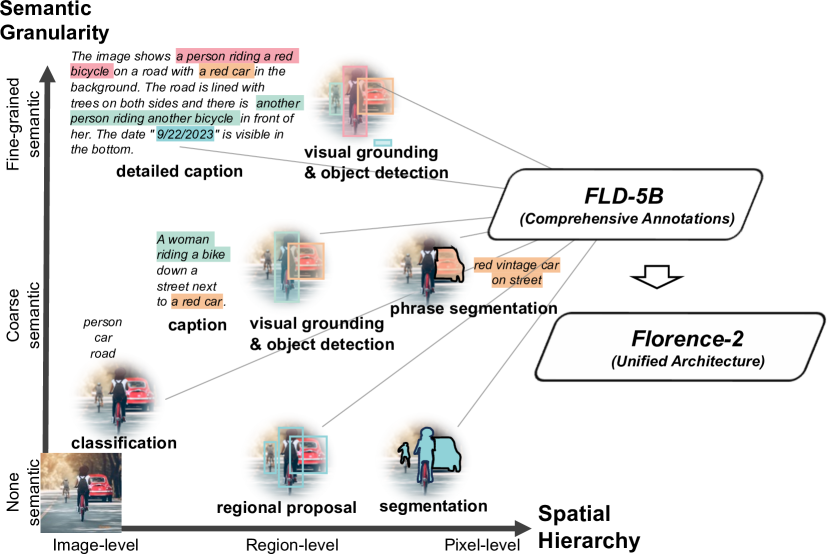
- タスク間の空間階層と意味的粒度を扱える、単一のアーキテクチャと重みを持つ universal vision foundation model の構築を目指す。
- 自律アノテーションと反復精錬を通じて、FLD-5Bという大規模で高品質なマルチタスクデータセットを作成し、データ不足を克服する。
- テキストプロンプトによるタスク活性化を可能にし、キャプショニング、グラウンディング、検出、セグメンテーションの分野でゼロショットおよびファインチューニングされた高性能を達成する。
提案手法
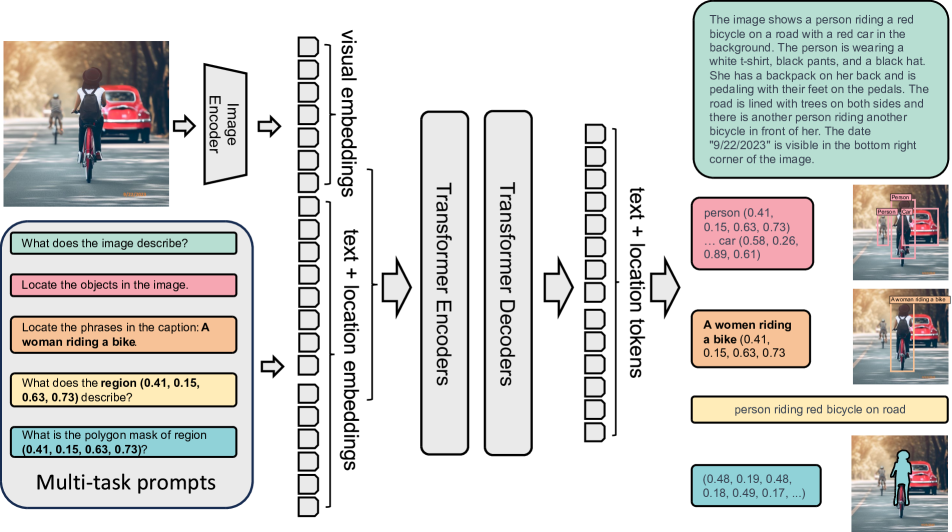
- 画像+プロンプトをテキストまたは領域出力へ翻訳する seq2seq フレームワークを使用する。
- DaViTベースのビジョンエンコーダとマルチモーダルエンコーダ-デコーダを採用し、視覚的トークンとテキストトークンを融合する。
- 領域ベースのタスクを表す領域座標を表現するために、トークナイザを 1,000 の location tokens で拡張する。
- 3段階のデータエンジン(初期専門家アノテーション、フィルタリング、反復的精錬)によって作成された、126M 枚の画像を跨ぐ 5.4B-annotation データセットである FLD-5B で訓練する。
- 画像レベル、領域/ピクセルレベル、細粒度の視覚意味合わせタスクに跨るマルチタスク目的を定式化する。
実験結果
リサーチクエスチョン
- RQ1単一モデル・統一アーキテクチャが、幅広いビジョンタスクで競争力のあるゼロショット性能を達成できるか。
- RQ2テキストプロンプト型タスク指示による大規模マルチタスク事前学習が、キャプショニング、グラウンディング、検出、セグメンテーションの分野で堅牢なFew-shotおよびファインチューニング能力を可能にするか。
- RQ3テキストプロンプトベースのタスク活性化が、1つのモデル内で多様なビジョンタスクを協調させる上でどのような影響を与えるか。
- RQ4Florence-2 のバックボーンをオブジェクト検出およびセグメンテーションのバックボーンとして使用した場合、下流タスクはどのように改善されるか。
- RQ5FLD-5Bデータエンジンの、大規模・多階層アノテーションのための利点と限界は何か。
主な発見
- Florence-2は、COCOキャプショニング、Flick30kグラウンディング、RefCOCO/+/g指示表現において新しいゼロショット状態を達成する。
- ファインチューニングされたFlorence-2は、その小型サイズにもかかわらず、RefCOCO/+/gベンチマークで新しい最先端の成果を達成する。
- 事前学習済みFlorence-2のバックボーンは、COCO物体検出、インスタンスセグメンテーション、およびADE20Kセマンティックセグメンテーションを、監視付き・自己教師付きベースラインを超えて向上させる。
- Florence-2-LはゼロショットでCOCOキャプショニングのCIDErを135.6に到達し、パラメータ数が少ない大規模モデルを上回る。
- FLD-5Bデータエンジンは、5Bのアノテーションと多様な空間的・意味的粒度を持つデータセットを生み出し、多才なマルチタスク学習を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。