[論文レビュー] Foundational Models Defining a New Era in Vision: A Survey and Outlook
視覚と言語の基盤モデルの包括的な調査で、アーキテクチャ、学習目的、データ、微調整、プロンプティング、課題を詳述し、将来の方向性を展望する。
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.
研究の動機と目的
- 視覚における基盤モデルを定義し、マルチモーダル理解における重要性を説明する。
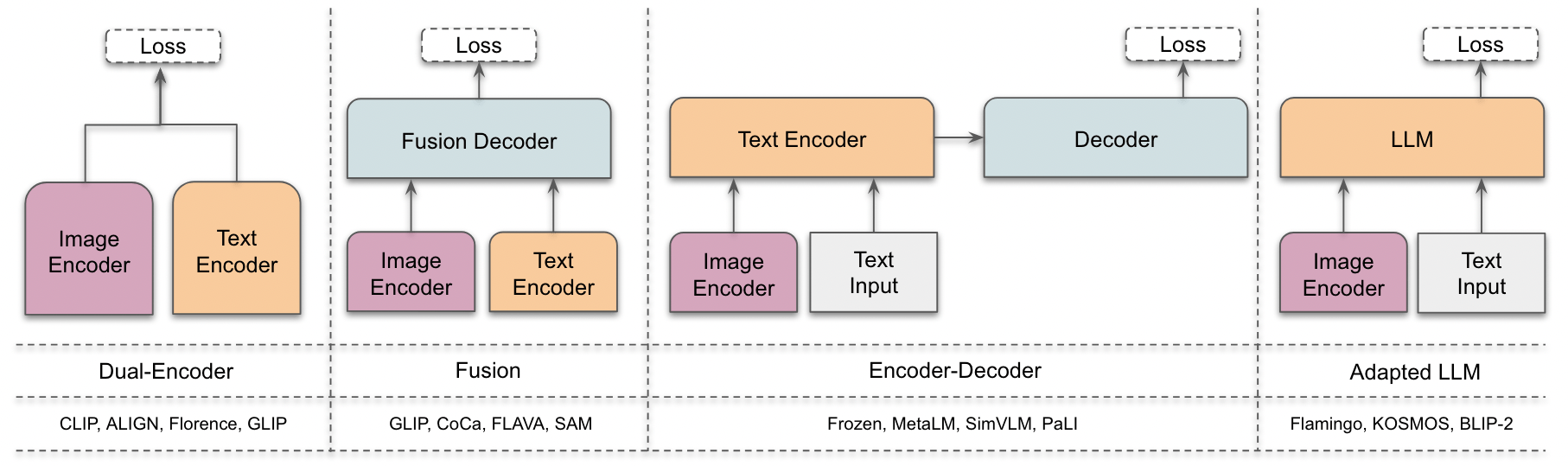
- アーキテクチャファミリー(デュアルエンコーダ、フュージョン、エンコーダ-デコーダ、適応型LLM)と学習目的(対比、生成、ハイブリッド)を調査する。
- 視覚言語モデルの事前学習データタイプ、微調整戦略、プロンプト設計を分析する。
- 評価、偏り、堅牢性、解釈性などのオープンな課題を議論し、今後の研究方向性を概説する。
提案手法
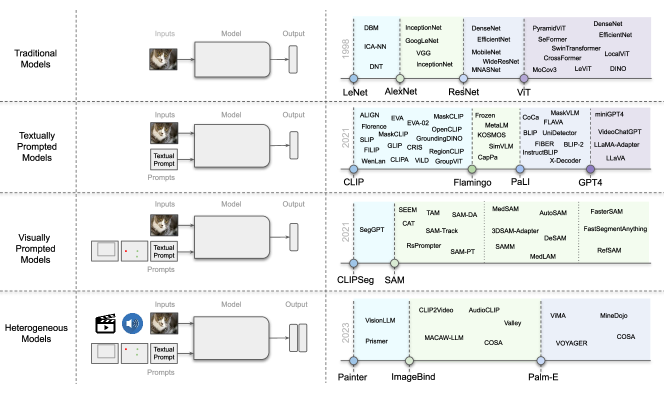
- テキスト指示型、視覚指示型、異種モダリティ、具象化モデルを横断した基盤視覚モデルの系統的レビュー。
- アーキテクチャをデュアルエンコーダ、フュージョン、エンコーダ-デコーダ、適応型LLM設計に分類し、例モデルを挙げる。
- 対照学習、生成、ハイブリッド損失を含む学習目的の統合と、代表例の定式化(例:ITC、MLM、LM)。
- 大規模事前学習データソースの概要(画像-テキストデータセット、部分的に合成データ、組み合わせ)とプロンプティング/微調整のパラダイム。
- 評価の課題、偏り、敵対的脆弱性、解釈性の問題について議論する。
- コミュニティリソース(GitHub)における最新の基盤モデルのリストをまとめる。
実験結果
リサーチクエスチョン
- RQ1視覚言語基盤モデルで用いられるアーキテクチャパターンは何で、プロンプトやモダリティごとにどう異なるか?
- RQ2学習目的とデータタイプが、視覚言語モデルの一般化と下流タスクの性能にどのように影響するか?
- RQ3基盤モデルを下流の視覚タスクに適応させるための一般的な微調整とプロンプティング戦略は何か?
- RQ4コンピュータビジョンの基盤モデルにおける主要な評価課題と今後の研究方向は何か?
- RQ5現在の基盤モデルは、マルチモーダル環境における偏り・頑健性・解釈性にどのように対処しているか?
主な発見
- 基盤モデルは、再学習なしにプロンプトを介して多くの視覚タスクへゼロショットおよびfew-shot転移を可能にする。
- テキスト指示型モデルは、対照(contrastive)、生成(generative)、ハイブリッドのアプローチに分類され、CLIPのようなアーキテクチャが基盤的である。
- 大規模な画像-テキストデータと多様な事前学習目的は、モデルの一般化と下流性能に大きく影響する。
- プロンプトエンジニアリングと微調整戦略(命令追従、グラウンディング、タスク固有の適応)は、これらのモデルを活用するうえで不可欠である。
- 評価の難しさ、現実世界での理解のギャップ、偏り、敵対的脆弱性、解釈性の懸念がオープンな課題として挙げられる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。