[論文レビュー] FoundationPose-TensorRT
FoundationPose は新規物体の 6D 姿勢推定とトラッキングの統一型基盤モデルであり、モデルベースとモデルフリーモ setup の両方で使用可能。神経的暗黙表現と大規模な合成データにより、ファインチューニング無しのテストタイム一般化を実現。
TensorRT-accelerated 6DoF object pose estimation and tracking based on FoundationPose. Given an RGB-D image, a 3D mesh of the object, and an initial segmentation mask, the model estimates the object pose and tracks it across subsequent frames. Credits The core inference code is derived from tao-toolkit-triton-apps, with the heavy Triton Inference Server dependencies removed and replaced by a direct TensorRT backend. The ONNX models are provided by isaac_ros_foundationpose. Setup 1. CUDA and TensorRT dependencies Install CUDA 12.4 + cuDNN 9.8 and TensorRT 10.9.0 into a local `deps/` folder: source scripts/deps.shactivate_deps This downloads and installs the dependencies locally - no system-wide installation required. The environment variables (`CUDA_HOME`, `TENSORRT_HOME`, `PATH`, `LD_LIBRARY_PATH`) are only active in the current shell session. Run `deactivate_deps` to restore the original environment. To use a different CUDA or TensorRT version, edit `scripts/deps.sh`. Make sure the PyTorch CUDA version matches (see step 2). 2. Python environment Create and activate a Python environment, e.g. with conda: conda create --name fp_tensorrt python=3.10conda activate fp_tensorrt Then install all Python dependencies (requires `activate_deps` to be active): source scripts/deps.sh && activate_depsbash scripts/setup.sh This installs PyTorch 2.5.0 (CUDA 12.4), nvdiffrast, pytorch3d, TensorRT Python bindings, and other required packages. 3. Model compilation Download the ONNX models from NVIDIA NGC and compile them into TensorRT engine files: bash scripts/convert_onnx.sh This produces weights/tensorrt/refiner_cs252.plan and weights/tensorrt/scorer_cs252.plan. chunk_size variable inside convert_onnx.sh controls the maximum batch size of the TensorRT engines (default: 252). A smaller value reduces VRAM usage, which is useful when tracking multiple objects simultaneously or on memory-constrained GPUs. To change it, edit the chunk_size variable before running and use the matching value in FoundationPoseWrapperConfig. Usage Demo Run the benchmark on the YCB mustard bottle sequence (demo data is downloaded automatically): source scripts/deps.sh && activate_depspython demo.py This runs initial pose estimation on the first frame and tracks the object across the remaining frames, printing per-frame poses and mean inference times. Python API from foundationpose_tensorrt import FoundationPoseWrapper, FoundationPoseWrapperConfig cfg = FoundationPoseWrapperConfig( downsample_width=None, # Set e.g. to 256 for faster inference at lower accuracy est_refine_iter=5, # Refinement iterations for initial pose estimation track_refine_iter=2, # Refinement iterations for tracking chunk_size=252, # Must match the `chunk_size` of the compiled TensorRT engine)wrapper = FoundationPoseWrapper(cfg=cfg) # Set camera intrinsics (3x3 numpy array)wrapper.set_camera_intrinsics(K) # Load object meshmesh = FoundationPoseWrapper.load_mesh("path/to/mesh.obj") # --- First frame ---wrapper.reset_scene(color, depth) # color: (H,W,3) uint8, depth: (H,W) float32 in meterspose = wrapper.add_object("object_name", mesh, mask) # mask: (H,W) bool # --- Subsequent frames ---poses = wrapper.step_scene(color, depth) # returns dict[name -> (4,4) numpy array] # Visualizevis = wrapper.render_results() # returns BGR image with projected bounding box and axes Poses are returned as 4x4 homogeneous transformation matrices (object-in-camera frame). Project structure scripts/ deps.sh # Install/activate CUDA, cuDNN, TensorRT locally setup.sh # Install Python dependencies convert_onnx.sh # Download ONNX models and compile to TensorRTsrc/foundationpose_tensorrt/ wrapper.py # High-level FoundationPoseWrapper API model.py # TensorRT engine wrapper and FoundationposeModel postprocessor.py # Rendering, cropping, and pose utilitiesweights/ onnx/ # Downloaded ONNX models tensorrt/ # Compiled TensorRT .plan filesdemo.py # Benchmark on YCB mustard data
研究の動機と目的
- 見知れない物体の堅牢な 6D 姿勢推定と多様なシナリオでのトラッキングを動機づける。
- 新規物体に対してモデルベースとモデルフリーモ setups の両方をサポートする単一のフレームワークを開発する。
- 合成データ生成、大規模な訓練、統一的なアーキテクチャ設計を通じて強い一般化を達成する。
- 神経的暗黙のオブジェクト表現を介してモデルベースとモデルフリーのギャップを橋渡しし、新しい視点合成を可能にする。
提案手法
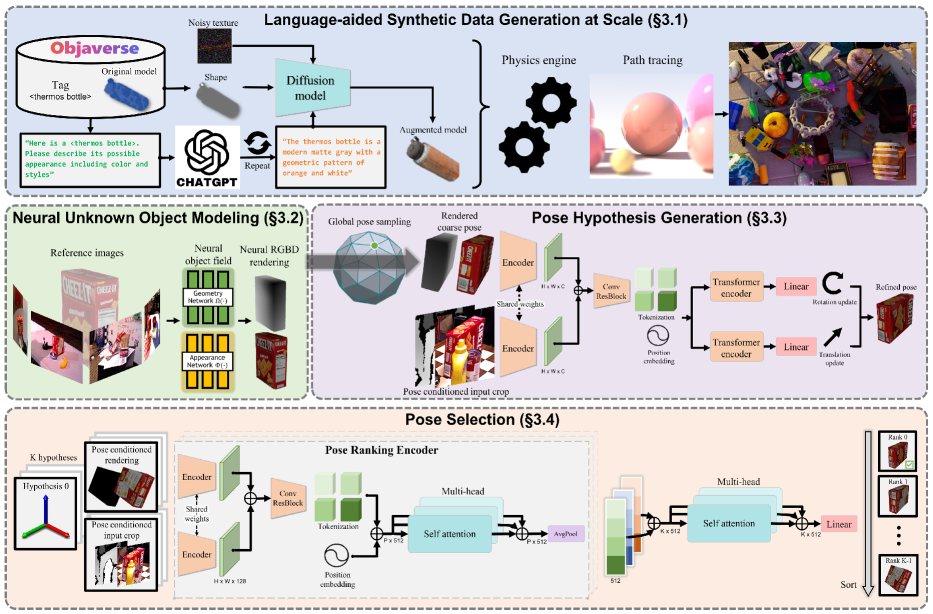
- RGBD レンダリングのためのオブジェクト中心の神経暗黙的(SDF ベース)オブジェクトフィールドを導入する。
- LLM- および拡散モデルを用いたテクスチャ拡張で合成テクスチャを多様化する。
- レンダリングビューから粗い姿勢仮説を更新するトランスフォーマーベースの姿勢改良ネットワークを訓練する。
- 階層的姿勢比較と対照的ランキング損失を備えた姿勢選択モジュールを実装する。
- テストタイム推論を、レンダリングと姿勢仮説の評価のための少数の参照ビューで実行する。
- 伝統的なグラフィックスパイプラインのドロップイン置換として機能するモデル非依存のレンダリングを提供する。
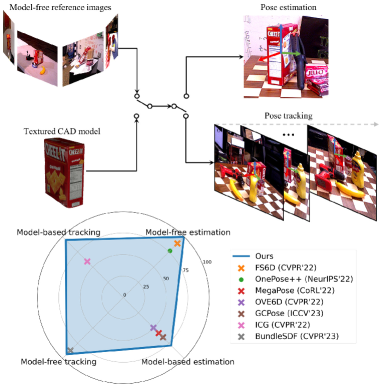
実験結果
リサーチクエスチョン
- RQ1単一の統一フレームワークは、モデルベースおよびモデルフリーの設定の下で新規物体の 6D 姿勢推定とトラッキングを実現できるか。
- RQ2神経暗黙のオブジェクト表現は、効果的な新規視点合成と様々な物体・テクスチャに対する堅牢な姿勢推定を可能にするか。
- RQ3LLM と拡散モデルによる補助を受けた合成データは、ファインチューニングなしで未知の物体へどこまで一般化できるか。
- RQ4階層的姿勢比較と対照的ランキングは、正確な姿勢選択にどのような利点をもたらすか。
主な発見
- 提案された FoundationPose フレームワークは、各タスク(姿勢推定またはトラッキング、モデルベースまたはモデルフリー)に特化した既存手法よりも優れている。
- novel objects に対するファインチューニングなしで、インスタンスレベルの手法と競合する成果を達成し、前提条件を緩和して動作する。
- 神経オブジェクトフィールドは効率的な RGBD レンダリングと効果的な姿勢仮説評価を可能にし、モデルベースとモデルフリーの設定を橋渡しする。
- LLM および拡散を用いたテクスチャ拡張がデータの多様性を著しく高め、合成訓練の一般化を改善する。
- 姿勢改良ネットワークと姿勢条件付きクロップ、階層的姿勢ランキングモジュールにより、オブジェクトごとのファインチューニングなしで正確な最終姿勢を得られる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。