[論文レビュー] FP8 versus INT8 for efficient deep learning inference
論文はデバイス上の推論の効率性のためにFP8とINT8を分析し、FP8は多くの場合INT8よりハードウェア効率と精度で劣るが、外れ値が多いトランスフォーマー系のケースを除くときには例外もある。全体として推論効率の面ではINT8が依然として望ましい選択肢である。
Recently, the idea of using FP8 as a number format for neural network training has been floating around the deep learning world. Given that most training is currently conducted with entire networks in FP32, or sometimes FP16 with mixed-precision, the step to having some parts of a network run in FP8 with 8-bit weights is an appealing potential speed-up for the generally costly and time-intensive training procedures in deep learning. A natural question arises regarding what this development means for efficient inference on edge devices. In the efficient inference device world, workloads are frequently executed in INT8. Sometimes going even as low as INT4 when efficiency calls for it. In this whitepaper, we compare the performance for both the FP8 and INT formats for efficient on-device inference. We theoretically show the difference between the INT and FP formats for neural networks and present a plethora of post-training quantization and quantization-aware-training results to show how this theory translates to practice. We also provide a hardware analysis showing that the FP formats are somewhere between 50-180% less efficient in terms of compute in dedicated hardware than the INT format. Based on our research and a read of the research field, we conclude that although the proposed FP8 format could be good for training, the results for inference do not warrant a dedicated implementation of FP8 in favor of INT8 for efficient inference. We show that our results are mostly consistent with previous findings but that important comparisons between the formats have thus far been lacking. Finally, we discuss what happens when FP8-trained networks are converted to INT8 and conclude with a brief discussion on the most efficient way for on-device deployment and an extensive suite of INT8 results for many models.
研究の動機と目的
- FP8をオンデバイス推論のINT8の潜在的代替として評価する動機づけ。
- 標準的なDLアクセラレータにおけるFP8とINT8のハードウェア面積とエネルギー影響を定量化する。
- 多様なモデルに対するポストトレーニング量子化(PTQ)と量子化なしトレーニング(QAT)の性能を評価する。
- FP8とINT8のトレードオフを踏まえたオンデバイス展開戦略の指針を提供する。
提案手法
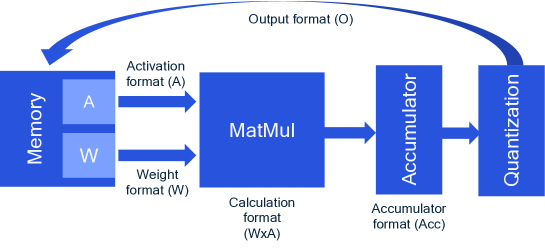
- FP8フォーマットを4桁または5桁の指数ビット(FP8-E4, FP8-E5)として定義し、INT8と比較してハードウェアと精度を評価する。
- 累積器実装(固定小数点Kulisch対浮動小数点)の理論分析とゲート数/面積への影響を推定する。
- CV、NLP、セグメンテーション、3Dを含む広範なモデルセットでPTQとQATの実験を実施し、精度を比較する。
- 重み・活性化分布の外れ値が量子化性能に与える影響を検討する。
- FP8で学習したネットワークをINT8へ変換して、変換後の精度影響を評価する。
実験結果
リサーチクエスチョン
- RQ1FP8(指数ビットが異なる場合)とINT8のオンデバイス推論におけるハードウェア効率(面積/電力)はどのように比較されるか。
- RQ2PTQおよびQATの下で、一般的なDLタスクに対してどのフォーマット(INT8対FP8-E4/FP8-E3/FP8-E2)が最も高い推論精度を示すか。
- RQ3実務的には、FP8ネットワークは競争力のある性能を得るために特別な取り扱い(例:トランスフォーマー固有の調整)が必要か。
- RQ4FP8で学習したネットワークをデプロイのためにINT8へ変換することの影響は何か。
- RQ5現実のエッジ展開において、FP8は推論より訓練(勾配)に適しているのか。
主な発見
- FP8-E4はINT8より著しく高いハードウェアコストを招く。FP8-E4は同等のアキュムレータに対して、FP32またはFP16の累積を用いた場合、INT8より50%以上多くのゲートを必要とする。
- アクティベーション帯域幅が支配的なネットワークでは、FP16/FP8の活性化がボトルネックとなり、INT8に対するFP8のスピードアップを低下させる。
- PTQの結果は、INT8がFP8-E4/E5よりも扱いが良いガウス様のネットワークでしばしば優れる一方で、外れ値が多いネットワーク(例:一部のトランスフォーマー層)ではFP8-E4/E5が勝ることがある。
- QATの結果は一般にフォーマット間でFP32性能を回復し、多くのCVネットワークではINT8が最良の結果を提供することが多く、FP8-E3はしばし FP8-E4より優れることが多い。
- 大半のネットワークにおいてFP8-E5は推論には不利であり、FP8-E4はQAT後の最適解としては希である。INT8またはFP8-E3/FP8-E2がより堅牢な精度を提供する。
- W4A8(4ビット重み、8ビット活性化)は一部のケースでFP8-E4と同等以上の性能を発揮することがあり、低精度フォーマットでの潜在的な効率向上を示唆する。
- FP8-E4で学習したモデルをINT8へ変換することは、いくつかのアーキテクチャで精度を維持またはわずかに向上させる場合があり、FP8トレーニングが競合的なINT8性能に必須ではないことを示唆している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。