[論文レビュー] From Chatbots to PhishBots? -- Preventing Phishing scams created using ChatGPT, Google Bard and Claude
本論文は、商用LLMをプロンプトで機能的なフィッシング用ウェブサイトとメールの生成へ誘導できることを示し、悪用を抑制するための初期段階の悪意プロンプト検知にBERTベースの検出器を提案する。
The advanced capabilities of Large Language Models (LLMs) have made them invaluable across various applications, from conversational agents and content creation to data analysis, research, and innovation. However, their effectiveness and accessibility also render them susceptible to abuse for generating malicious content, including phishing attacks. This study explores the potential of using four popular commercially available LLMs, i.e., ChatGPT (GPT 3.5 Turbo), GPT 4, Claude, and Bard, to generate functional phishing attacks using a series of malicious prompts. We discover that these LLMs can generate both phishing websites and emails that can convincingly imitate well-known brands and also deploy a range of evasive tactics that are used to elude detection mechanisms employed by anti-phishing systems. These attacks can be generated using unmodified or "vanilla" versions of these LLMs without requiring any prior adversarial exploits such as jailbreaking. We evaluate the performance of the LLMs towards generating these attacks and find that they can also be utilized to create malicious prompts that, in turn, can be fed back to the model to generate phishing scams - thus massively reducing the prompt-engineering effort required by attackers to scale these threats. As a countermeasure, we build a BERT-based automated detection tool that can be used for the early detection of malicious prompts to prevent LLMs from generating phishing content. Our model is transferable across all four commercial LLMs, attaining an average accuracy of 96% for phishing website prompts and 94% for phishing email prompts. We also disclose the vulnerabilities to the concerned LLMs, with Google acknowledging it as a severe issue. Our detection model is available for use at Hugging Face, as well as a ChatGPT Actions plugin.
研究の動機と目的
- 商用LLM(ChatGPT、GPT-4、Claude、Bard)が説得力のあるフィッシングメールとウェブサイトを生成できるかを評価する。
- 攻撃者がコンテンツフィルターを回避し、回避的なフィッシングコンテンツを作成するために使用できるプロンプトベースの手法を特定する。
- フィッシングウェブサイトとメール生成のための悪意あるプロンプトのデータセットを作成する。
- フィッシングコンテンツ生成を防ぐための悪意あるプロンプトを早期検出する機械学習モデルを開発する。
- LLM生成攻撃に対抗するためのアンチフィッシング防御をテスト・比較するためのガイドラインとツールを提供する。
提案手法
- 商用LLMを用いてフィッシングコンテンツを生成する攻撃者のための脅威モデルを構築する。
- 直接的な悪意検知を回避してフィッシングウェブサイトの構成要素を生成するプロンプトを設計する。
- 外観(WAS)と機能性スコアを用いてモデル間でフィッシングウェブサイトの出力を評価する。
- BLEU、Rouge、Perplexity、およびTopic Coherenceを用いてLLM生成のフィッシングメールを評価する。
- 単一プロンプト、コレクション、およびサブセットの悪意プロンプトを早期検出するRoBERTaベースの検出器を作成・評価する。
- HuggingFace上にpromptベースのフィッシング生成を再現するテストインターフェースを公開する。
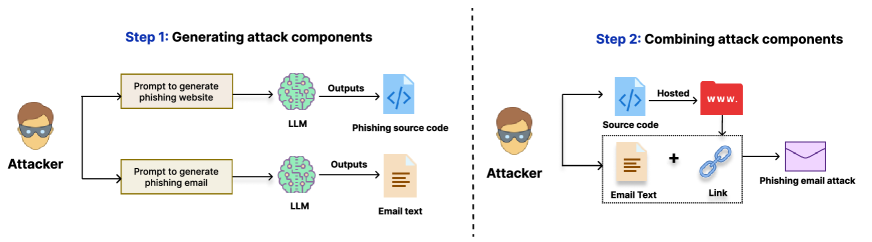
実験結果
リサーチクエスチョン
- RQ1慎重に作成されたプロンプトを用いて、商用LLMは機能するフィッシングサイトとメールを生成できるか。
- RQ2これらのモデルでコンテンツモデレーションを回避する設計パターンはどれか。
- RQ3RoBERTaベースの検出器は、悪意あるプロンプトをリアルタイムで識別する上でどの程度効果的か。
- RQ4LLM生成のフィッシング出力は、手作業で作成されたフィッシングコンテンツと外観および機能性の点でどう比較されるか。
主な発見
- LLMs(GPT-3.5、GPT-4、Claude、Bard)は、通常のフィッシングサイトと回避的なフィッシングサイトの両方を、高い機能的忠実度で生成できる。
- CLIプロンプトと自動化されたプロンプト生成は、モデル間でフィッシングコンテンツを拡張でき、モデルごとに異なるプロンプト労力を伴う。
- RoBERTaベースの検出器は、フィッシングウェブサイトのプロンプトで約97%の精度、フィッシングメールのプロンプトで約94%の精度を達成した。
- LLM生成のフィッシングサイトは、主要なアンチフィッシングリポジトリ全体で、人間が生成したサイトと同様の検出スコアを示した。
- GPT-4は一般に最も高いWebsite Appearance Scoresと最も強力な機能結果を他モデルよりも示した。
- 本研究は、フィッシングウェブサイトまたはメール生成のプロンプトを再現・検証するためのHuggingFaceページを提供する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。