[論文レビュー] From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future
ソフトウェア工学における LLM と LLM ベースのエージェントを区別する調査。六つの SE ドメイン、ベンチマーク、今後の方向性を網羅。
With the rise of large language models (LLMs), researchers are increasingly exploring their applications in var ious vertical domains, such as software engineering. LLMs have achieved remarkable success in areas including code generation and vulnerability detection. However, they also exhibit numerous limitations and shortcomings. LLM-based agents, a novel tech nology with the potential for Artificial General Intelligence (AGI), combine LLMs as the core for decision-making and action-taking, addressing some of the inherent limitations of LLMs such as lack of autonomy and self-improvement. Despite numerous studies and surveys exploring the possibility of using LLMs in software engineering, it lacks a clear distinction between LLMs and LLM based agents. It is still in its early stage for a unified standard and benchmarking to qualify an LLM solution as an LLM-based agent in its domain. In this survey, we broadly investigate the current practice and solutions for LLMs and LLM-based agents for software engineering. In particular we summarise six key topics: requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance. We review and differentiate the work of LLMs and LLM-based agents from these six topics, examining their differences and similarities in tasks, benchmarks, and evaluation metrics. Finally, we discuss the models and benchmarks used, providing a comprehensive analysis of their applications and effectiveness in software engineering. We anticipate this work will shed some lights on pushing the boundaries of LLM-based agents in software engineering for future research.
研究の動機と目的
- ソフトウェア工学における LLM と LLM ベースのエージェントの区別を説明する。
- 六つの SE ドメインを調査して、タスク、ベンチマーク、評価指標を整理する。
- 最先端の技術、データセット、実験的方法を特定する。
- 文脈長、幻覚、ツール統合などの課題を強調する。
- LLM ベースのエージェントを用いた SE の今後の研究とベンチマーキングに向けた指針を提供する。
提案手法
- DBLP と arXiv の文献収集。2023年後半から2024年5月までを対象。
- LLM でない論文や低品質の投稿を除外する手動スクリーニング。
- スノーボール検索で当初見逃した影響力のある論文を網羅。
- 六つの SE ドメインにわたる LLM と LLM ベースのエージェントを区別するカテゴリ分析。
- LLMs とエージェント間のタスク、ベンチマーク、評価指標の比較。
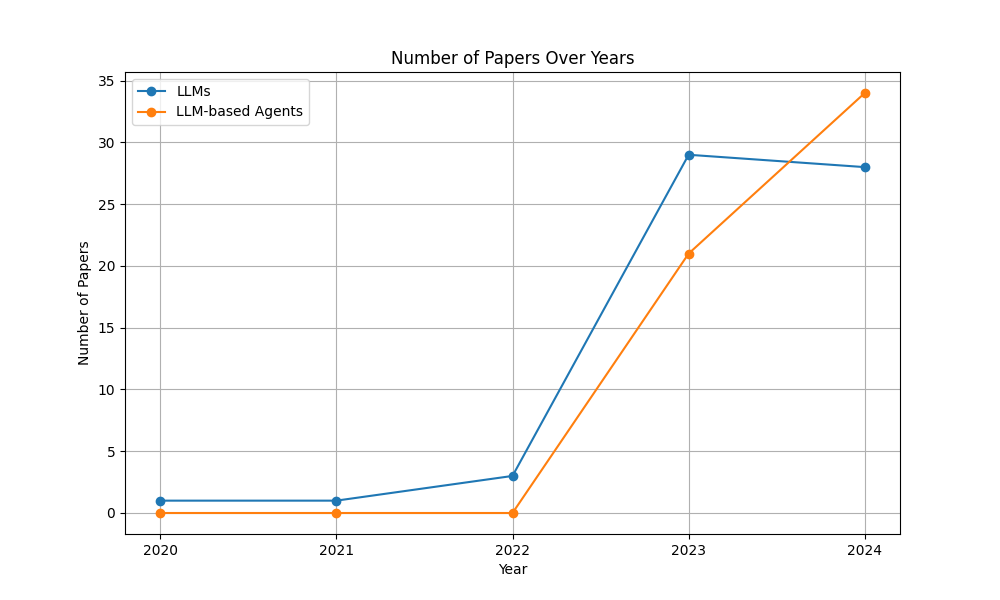
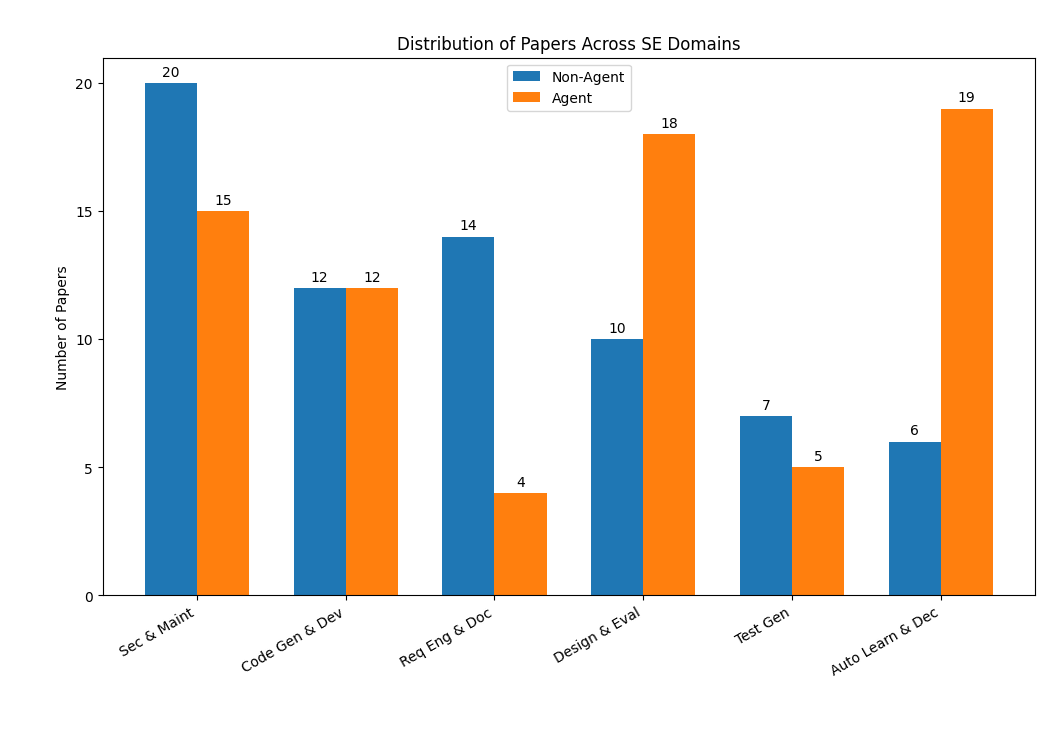
実験結果
リサーチクエスチョン
- RQ1RQ1: SE における LLM および LLM ベースのエージェントの最新技術と実践は何か?
- RQ2RQ2: SE アプリケーションにおけるタスク性能の LLM と LLM ベースのエージェントの主要な違いは何か?
- RQ3RQ3: SE のタスクで LLM および LLM ベースのエージェントの性能評価に最もよく使われるベンチマークデータセットと評価指標は何か?
- RQ4RQ4: SE で LLM を用いる際の主な実験モデルと方法論は何か?
主な発見
- 本調査は LLM を LLM ベースのエージェントと区別し、それらを六つの SE ドメインに対応づけている。
- SE における LLM とエージェントの評価に用いられるベンチマークと指標を分析している。
- SE における LLM ベースのエージェント用の統一基準とベンチマークの不足を指摘している。
- アーキテクチャ、RAG、ツール利用を主要な実現技術として整理している。
- 単一エージェント系と多エージェント系の議論と、それらが文脈管理と堅牢性に与える影響を扱っている。
- 現在の応用と今後の研究方向の総合的な展望をまとめている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。