[論文レビュー] From paintbrush to pixel: A review of deep neural networks in AI-generated art
この論文はAI生成アートに使用される深層ニューラルネットワークアーキテクチャを概観し、DeepDreamから拡散型モデルまでのマイルストーンを追跡し、それらの長所と制限を比較します。
This paper delves into the fascinating field of AI-generated art and explores the various deep neural network architectures and models that have been utilized to create it. From the classic convolutional networks to the cutting-edge diffusion models, we examine the key players in the field. We explain the general structures and working principles of these neural networks. Then, we showcase examples of milestones, starting with the dreamy landscapes of DeepDream and moving on to the most recent developments, including Stable Diffusion and DALL-E 3, which produce mesmerizing images. We provide a detailed comparison of these models, highlighting their strengths and limitations, and examining the remarkable progress that deep neural networks have made so far in a short period of time. With a unique blend of technical explanations and insights into the current state of AI-generated art, this paper exemplifies how art and computer science interact.
研究の動機と目的
- Map the key neural network families used in AI-generated art (CNNs, autoencoders, GANs, Transformers, diffusion models).
- Explain the building blocks and working principles of these models to readers from technical and non-technical backgrounds.
- Highlight milestones and representative models (e.g., DeepDream, GANs, pix2pix, CycleGAN, GauGAN, DALL-E, Stable Diffusion).
- Provide a technical comparison of current state-of-the-art models and discuss strengths and limitations.
提案手法
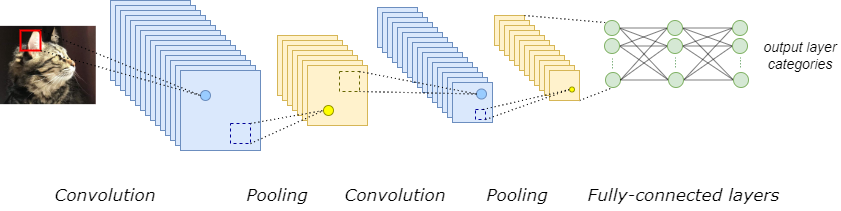
- Describe CNN architectures and their typical layers (convolution, pooling, fully-connected) and loss functions.
- Explain autoencoders and variational autoencoders and their role in representation learning and generation.
- Detail Generative Adversarial Networks and variations (DCGAN, StyleGAN, Pix2Pix, CycleGAN, SAGAN).
- Introduce Transformers and self-attention, including Vision Transformer and image generation adaptations.
- Explain diffusion models and their forward (noising) and reverse (denoising) processes, with optional text guidance via transformers.

実験結果
リサーチクエスチョン
- RQ1What neural network architectures have driven the development of AI-generated art?
- RQ2How do these architectures differ in structure, training, and generation capabilities?
- RQ3What milestones illustrate the progression from early visualization methods to modern diffusion and text-to-image systems?
- RQ4What are the strengths and limitations of current state-of-the-art AI-generated art models?
- RQ5How do text prompts influence diffusion and transformer-based image generation?
主な発見
- The review identifies CNNs, GANs, Transformers, and diffusion models as central to AI-generated art.
- Milestones include DeepDream, pix2pix, CycleGAN, GauGAN, DALL-E, and diffusion-based systems like Stable Diffusion and Midjourney-related tools.
- Diffusion models are highlighted as outperforming GANs in image synthesis and enabling high-quality text-to-image generation.
- Transformer-based image generation (Vision Transformer) enables efficient image classification and generation with fewer parameters.
- GauGAN and its successors show how semantic maps and style transfer enable controllable, photorealistic outputs.
- The paper emphasizes ongoing progress and the interaction between art and computer science, along with limitations and ethical considerations.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。