[論文レビュー] Frozen Transformers in Language Models Are Effective Visual Encoder Layers
本論文は、事前学習済みLLMの凍結されたトランスフォーマーブロックが、言語プロンプトやマルチモーダル事前学習なしで、2D/3Dおよびビジョン-言語タスクの幅広い範囲で有効な視覚エンコーダ層として機能し得ることを示している。
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
研究の動機と目的
- 凍結されたLLMトランスフォーマーブロックが、純粋に視覚的タスクのための汎用的な視覚エンコーダとして機能することを示す。
- このアプローチが、言語入力に依存せず、多様なタスクとモダリティ全体で性能を向上させることを示す。
- 事前学習済みLLMが情報フィルタリング機構を介して視覚エンコーディングを強化する理由の説明を提案する。
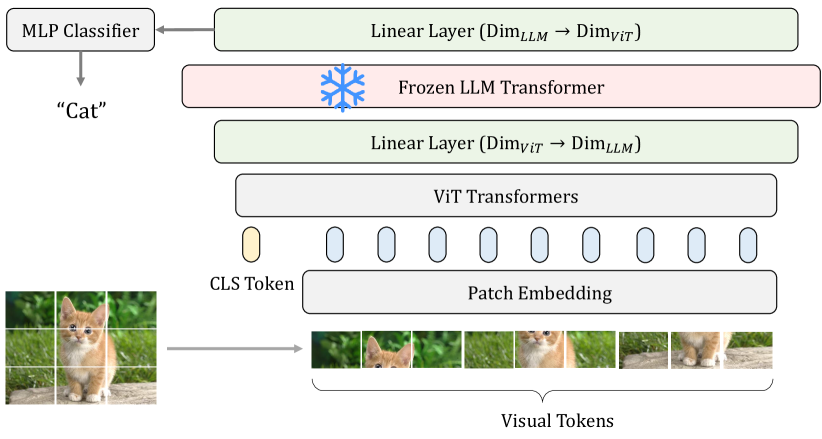
提案手法
- 視覚エンコーダとデコーダの間に凍結されたLLMトランスフォーマーブロックを挿入し、次元を揃えるための学習可能な線形層を前後に配置する。
- トレーニング中はLLMブロックを凍結したまま、他のすべてのモジュールを訓練する。
- 2D/3D分類、動作認識、モーション予測、ビジョン-言語タスクを含む多様なタスクで評価する。
- 異なるLLM(例:LLaMA、OPT)および異なるトランスフォーマーブロックを用いて結果を比較し、汎用性を示す。
- 情報フィルタリング仮説を提案し、有意義な視覚トークンを強調することで視覚エンコーディングの改善を説明する。
- 画像、点群、ビデオ、モーション予測、およびVLベンチマークに対する実装と実験を提供する。
実験結果
リサーチクエスチョン
- RQ1事前学習済みLLMの凍結トランスフォーマーブロックは、言語プロンプトなしで効果的な視覚エンコーダとして機能し得るか?
- RQ2凍結されたLLMトランスフォーマーは、視覚タスクおよびビジョン-言語タスクの広範な領域で性能を向上させるか?
- RQ3LLMトランスフォーマーが視覚エンコーディングを助ける理由を説明するメカニズムは何か(例:有意義なトークンの情報フィルタリング)?
主な発見
- 視覚エンコーダの上に凍結されたLLMトランスフォーマーブロックを組み込むことで、画像分類ベンチマーク全体で精度と頑健性が一貫して向上する。
- この改善は、2Dおよび3D認識タスク、ビデオアクション認識、モーション予測、2D/3Dビジョン-言語タスクに及ぶ。
- 利点は、異なるLLM(例:LLaMA、OPT)および異なるトランスフォーマーブロックに対して汎用性を示す。
- LLMトランスフォーマーのファインチューニングは性能を低下させる可能性があり、凍結する方がしばしばより効果的で簡便であることを示唆する。
- 情報フィルタリング仮説は、凍結されたLLMトランスフォーマーが有意義な視覚トークンを集中させるのに役立ち、下流での影響を高めると説明する。
- より大規模なLLMと適切なトランスフォーマー層の選択が、改善を達成するうえで重要である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。