[論文レビュー] Fully Convolutional Speech Recognition
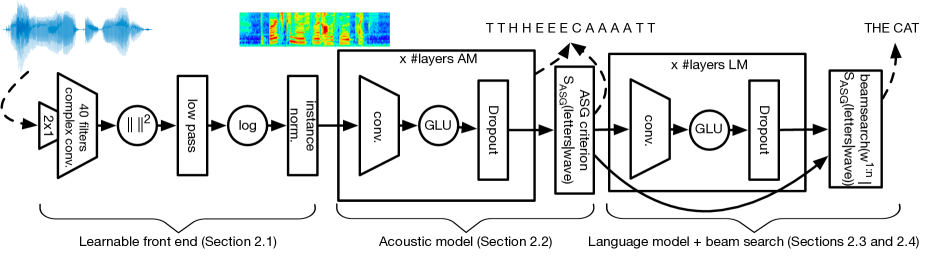
本論文は、生の波形上で動作し、学習可能なフロントエンドと畳み込み言語モデルを備えた完全畳み込みのエンドツーエンド音声認識システムを提示し、WSJとLibriSpeechにおけるエンドツーエンドシステムの中で最先端の結果を達成します。
Current state-of-the-art speech recognition systems build on recurrent neural networks for acoustic and/or language modeling, and rely on feature extraction pipelines to extract mel-filterbanks or cepstral coefficients. In this paper we present an alternative approach based solely on convolutional neural networks, leveraging recent advances in acoustic models from the raw waveform and language modeling. This fully convolutional approach is trained end-to-end to predict characters from the raw waveform, removing the feature extraction step altogether. An external convolutional language model is used to decode words. On Wall Street Journal, our model matches the current state-of-the-art. On Librispeech, we report state-of-the-art performance among end-to-end models, including Deep Speech 2 trained with 12 times more acoustic data and significantly more linguistic data.
研究の動機と目的
- エンドツーエンドASRのために、再帰的アーキテクチャを完全畳み込みネットワークに置換する動機づけ。
- 手作り特徴量を用いず、生の波形からのエンドツーエンド訓練を実証する。
- ASRのデコーディングに畳み込み言語モデルを導入する。
- 大語彙データセット(WSJとLibrispeech)で評価し、エンドツーエンドシステムの中で最先端を確立する。
- 学習可能なフロントエンドの解析と、それが性能に与える影響を、特に騒がしい条件下で分析する。
提案手法
- プレエンファシスを模倣し、生の波形から特徴量に似た表現を計算する学習可能なフロントエンド。
- Auto Segmentation Criterion (ASG)を用いて文字を予測するよう訓練された、ゲート付きリニアユニットを備えた深層畳み込み音響モデル。
- ビームサーチ中の転写を評価するために用いられる畳み込み言語モデル(GCNN-14B)。
- LM重み、単語挿入報酬、無音ペナルティのハイパーパラメータを調整した畳み込みLMと組み合わせた、音響モデルスコアを組み込んだビームサーチデコーディング。
- WSJ (80時間) と Librispeech (1000時間) での訓練と評価、データセット固有の言語モデル訓練データとハイパーパラメータの調整を併用。
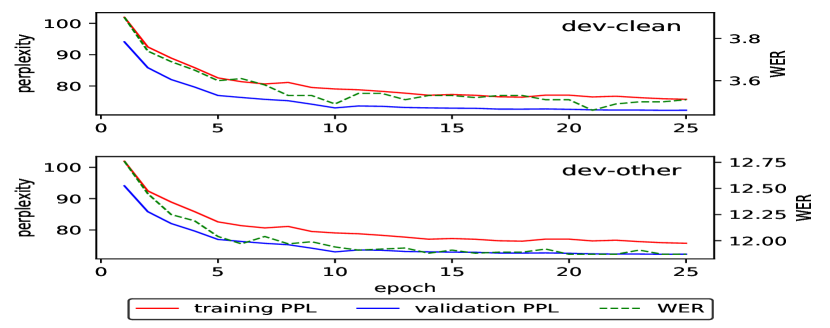
実験結果
リサーチクエスチョン
- RQ1エンドツーエンドASRにおける音響モデルと言語モデルのために、完全畳み込みアーキテクチャは再帰アーキテクチャに匹敵するか、あるいはそれを超えるか。
- RQ2生の波形からフロントエンドを学習することは、従来のメルフィルタバンク特徴より有利か、特に騒音条件下で?
- RQ3畳み込み言語モデルを統合することは、従来のn-gram言語モデルと比較してデコーディング性能を向上させるか?
- RQ4学習可能なフロントエンドのフィルタ数とLMのコンテキストを変更することが、WSJとLibrispeechにおけるWERにどのような影響を与えるか?
- RQ5WSJとLibrispeechにおける最先端システムと比較したとき、エンドツーエンドCNNベースのASRはどう機能するか?
主な発見
- 完全畳み込みモデルは、エンドツーエンドシステムとしてWSJにおける現状の最先端と同等である。
- Librispeechでは、DeepSpeech 2を含むエンドツーエンドモデルの中で最先端の性能を達成し、騒音付きテストセットで2%絶対WER削減、クリーン音声で約0.5%を達成。
- 畳み込み言語モデルは4-gramLMに対して系統的な改善をもたらし、より良い困惑度とより大きな受容野を実現。
- 生の波形からフロントエンドを学習することは、特に騒音データで性能を改善し、学習可能なフィルタ数を増やすとさらに改善が得られる(例:Librispeech騒音テストセットでの絶対WERが1.5%減少)。
- 学習済みフロントエンドのフィルタは、メル様式の低周波帯域に偏ったスペクトルの周りに集まる傾向があり、ASRにはメルスケールが最適でない可能性を示唆している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。