[論文レビュー] FwdLLM: Efficient FedLLM using Forward Gradient
FwdLLMは前向き勾配とPEFTを用いたBP-freeトレーニングを導入し、モバイル端末上でのLLMの実用的なフェデレーテッド微調整を可能にし、大幅な高速化とメモリ削減を実現する。
Large Language Models (LLMs) are transforming the landscape of mobile intelligence. Federated Learning (FL), a method to preserve user data privacy, is often employed in fine-tuning LLMs to downstream mobile tasks, an approach known as FedLLM. Though recent efforts have addressed the network issue induced by the vast model size, they have not practically mitigated vital challenges concerning integration with mobile devices, such as significant memory consumption and sluggish model convergence. In response to these challenges, this work introduces FwdLLM, an innovative FL protocol designed to enhance the FedLLM efficiency. The key idea of FwdLLM to employ backpropagation (BP)-free training methods, requiring devices only to execute ``perturbed inferences''. Consequently, FwdLLM delivers way better memory efficiency and time efficiency (expedited by mobile NPUs and an expanded array of participant devices). FwdLLM centers around three key designs: (1) it combines BP-free training with parameter-efficient training methods, an essential way to scale the approach to the LLM era; (2) it systematically and adaptively allocates computational loads across devices, striking a careful balance between convergence speed and accuracy; (3) it discriminatively samples perturbed predictions that are more valuable to model convergence. Comprehensive experiments with five LLMs and three NLP tasks illustrate FwdLLM's significant advantages over conventional methods, including up to three orders of magnitude faster convergence and a 14.6x reduction in memory footprint. Uniquely, FwdLLM paves the way for federated learning of billion-parameter LLMs such as LLaMA on COTS mobile devices -- a feat previously unattained.
研究の動機と目的
- モバイルデバイス上でのFedLLMの実用性を妨げるメモリ、アクセラレータ、スケーラビリティの制約を動機づける。
- 摂動推論を介したBP-freeトレーニングを提案し、デバイス上のメモリと計算を削減する。
- 前向き勾配トレーニングとPEFT手法を統合し、大規模LLMへ拡張する。
- 適応的な摂動ペーシングと識別的摂動サンプリングを開発して収束を加速する。
- 複数のモデルとタスクにわたって、デバイス上での実現性を示し、性能向上を定量化する。
提案手法
- BP-freeトレーニングを真の勾配の無偏推定量として前向き勾配を使用して実現する。
- BP-freeトレーニングをLoRaやAdapterのようなパラメータ効率的ファインチューニング(PEFT)手法と組み合わせる。
- 前向き勾配の分散が閾値を下回るときだけ勾配を集約する、分散制御ペーシング機構を実装する。
- 真の勾配とのコサイン類似度が高い摂動を識別的にサンプリングし、低価値の摂動を除外する。
- 勾配類似性に基づいてモデルごとに適切なPEFT手法を選択する自動オフラインPEFTプロファイラを採用する。
- 摂動とデバイス参加を適応的に管理するクラウド-デバイススケジューリングワークフローを活用する。
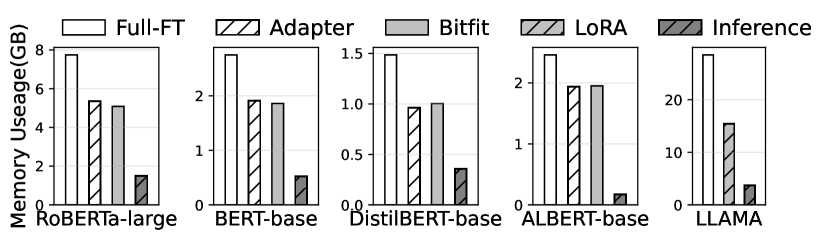
実験結果
リサーチクエスチョン
- RQ1BP-free前向き勾配トレーニングとPEFTはモバイルデバイス上で実用的なFedLLMを実現できるか?
- RQ2収束速度と計算コストのバランスをとるために、摂動ペーシングとサンプリングを自動化するには?
- RQ3フルモデル微調整およびPEFTベースラインと比較して、どの程度のメモリ・時間・精度の改善が達成可能か?
- RQ4COTSモバイルハードウェア上でビリオンパラメータLLM(例:LLaMA)のフェデレートベンチマークは実現可能か?
主な発見
- フルモデル微調整と比較して最大で217.3×の収束速度改善。
- 強力なベースラインと比較してメモリフットプリントを最大14.6×削減。
- 記述された設定ごとに、デバイス上のトレーニング時間が10.9–97.9時間から0.2–0.8時間に減少。
- ベースラインに対して、BP-free + PEFTで平均10.6×の高速化、範囲は2.0×–93.4×。
- INT4量子化時に、消費者向けスマートフォン上で7B LLaMAモデルの微調整を10分以内に実証。
- 識別的摂動サンプリングと分散制御ペーシングが収束効率に顕著な影響を与えることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。