[論文レビュー] GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
GaLore はメモリ効率の高い勾配低ランク投影を用いて全パラメータモデルを訓練し、LLMの事前学習およびファインチューニング中の性能を保ちながらオプティマイザーステートのメモリを大幅に削減します。
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
研究の動機と目的
- Motivate the memory bottlenecks in pre-training and fine-tuning large language models.
- Propose gradient-based low-rank projections to reduce optimizer memory without constraining full parameter learning.
- Demonstrate memory and performance benefits on LLaMA-7B pre-training and RoBERTa-GLE fine-tuning.
- Show compatibility with existing optimizers and memory-saving techniques.
提案手法
- Weight gradients が訓練中低ランクになるという観察を活用する(Lemma 3.1 および関連).
- P in R^{m×r} および Q in R^{n×r} の2つの射影行列を導入し、勾配更新に P^T G Q を形成する.
- weights を tilde{G}_t = P_t ρ_t(P_t^T G_t Q_t) Q_t^T で更新し、全パラメータ学習を保持する.
- スケジュールされたインターバル(T)で SVDベースの射影を用いて P と Q を再初期化することで部分空間の切り替えを許容する.
- 収束解析(Theorem 3.6)を提供し、 GaLore が固定または周期的に更新される射影の下で収束することを示す.
- Adam、8-bit Adam、Adafactor、および層ごとの重み更新との互換性を示す.
- メモリ効率のあるオプティマイザと組み合わせてさらにメモリを削減する。
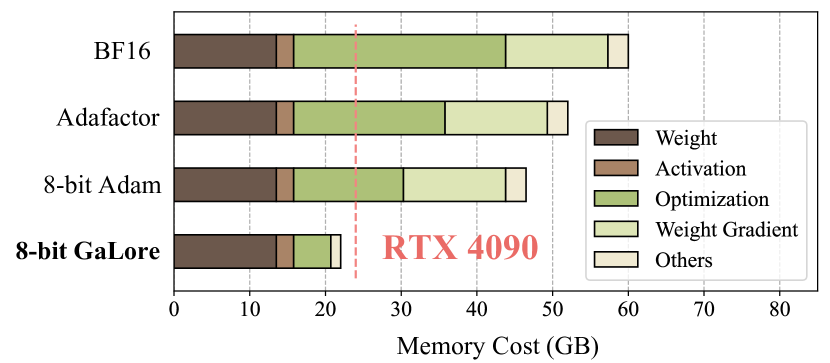
実験結果
リサーチクエスチョン
- RQ1LLM 訓練中の勾配行列を低ランクとして効果的に扱い、性能を損なうことなくメモリを削減できるか?
- RQ2GaLore は LoRA ベース手法と同等またはそれ以上のメモリ節約を達成しつつ、全パラメータ学習を保持するか?
- RQ3部分空間の切替頻度と階数が収束および最終モデル品質にどう影響するか?
- RQ4GaLore は一般的なメモリ効率化オプティマイザとトレーニング体制(事前学習と微調整)と互換性があるか?
主な発見
| Metric | GaLore | LoRA |
|---|---|---|
| Weights | mn | mn+mr+nr |
| Optim States | mr+2nr | 2mr+2nr |
| Multi-Subspace | ✓ | ✗ |
| Pre-Training | ✓ | ✗ |
| Fine-Tuning | ✓ | ✓ |
- GaLore は 8-bit オプティマイザ使用時に BF16 ベースラインと比較して最適化メモリを最大で 65.5% 削減し、総訓練メモリも最大で 63.3% 削減する。
- C4 上での LLaMA 7B 事前学習(19.7B トークン)において、8-bit GaLore はフルランク訓練と同等のパープレックスティを、はるかに少ないメモリで達成する;一部設定では r が大きい場合、フルランクの性能に近づくまたは若干上回る。
- GaLore は 24GB メモリの消費者向けGPU(例: RTX 4090)上でモデル並列化・チェックポイント・オフローディングなしで 7B モデルの事前学習を実現可能(活性化チェックポイントを用いればバッチサイズをさらに拡張可能)。
- RoBERTa-Base の GLUE 微調整では GaLore(rank 4)が LoRA より平均 GLUE スコアで上回り(85.89 vs 85.61)、同程度かそれ以下のメモリフットプリントで競合的な利得を提供;GaLore の rank 8 でも競争力の利得を得られる。
- GaLore はオプティマイザに依存せず、AdamW、8-bit Adam、Adafactor と互換性があり、追加のメモリ節約のための層ごとの重み更新をサポートする。
![Figure 2 : Learning through low-rank subspaces $\Delta W_{T_{1}}$ and $\Delta W_{T_{2}}$ using GaLore. For $t_{1}\in[0,T_{1}-1]$ , $W$ are updated by projected gradients $\tilde{G}_{t_{1}}$ in a subspace determined by fixed $P_{t_{1}}$ and $Q_{t_{1}}$ . After $T_{1}$ steps, the subspace is changed b](https://ar5iv.labs.arxiv.org/html/2403.03507/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。