[論文レビュー] garak: A Framework for Security Probing Large Language Models
garak は、LLM の構造化されたレッドチーミングとセキュリティ監査のためのオープンソースフレームワークで、脆弱性を発見するためのプローブ、検出器、バフの生成を可能にします。整合性とポリシー決定を inform するために、探査をベンチマークより重視します。
As Large Language Models (LLMs) are deployed and integrated into thousands of applications, the need for scalable evaluation of how models respond to adversarial attacks grows rapidly. However, LLM security is a moving target: models produce unpredictable output, are constantly updated, and the potential adversary is highly diverse: anyone with access to the internet and a decent command of natural language. Further, what constitutes a security weak in one context may not be an issue in a different context; one-fits-all guardrails remain theoretical. In this paper, we argue that it is time to rethink what constitutes ``LLM security'', and pursue a holistic approach to LLM security evaluation, where exploration and discovery of issues are central. To this end, this paper introduces garak (Generative AI Red-teaming and Assessment Kit), a framework which can be used to discover and identify vulnerabilities in a target LLM or dialog system. garak probes an LLM in a structured fashion to discover potential vulnerabilities. The outputs of the framework describe a target model's weaknesses, contribute to an informed discussion of what composes vulnerabilities in unique contexts, and can inform alignment and policy discussions for LLM deployment.
研究の動機と目的
- LLMセキュリティの探査と発見を支援する、 holistic な構造化アプローチを動機づける。
- 対象のLLMや対話システムの脆弱性を検出・記述する柔軟なフレームワークを提供する。
- 多様なジェネレータとデプロイメント文脈に跨るエンドツーエンドのテストを可能にする。
- 弱点を明らかにするためのプローブ、検出器、攻撃生成機の拡張可能なスイートを提供する。
- ポリシー決定を情報するためのレッドチーム作業の報告と脆弱性データベースへの統合を容易にする。
提案手法
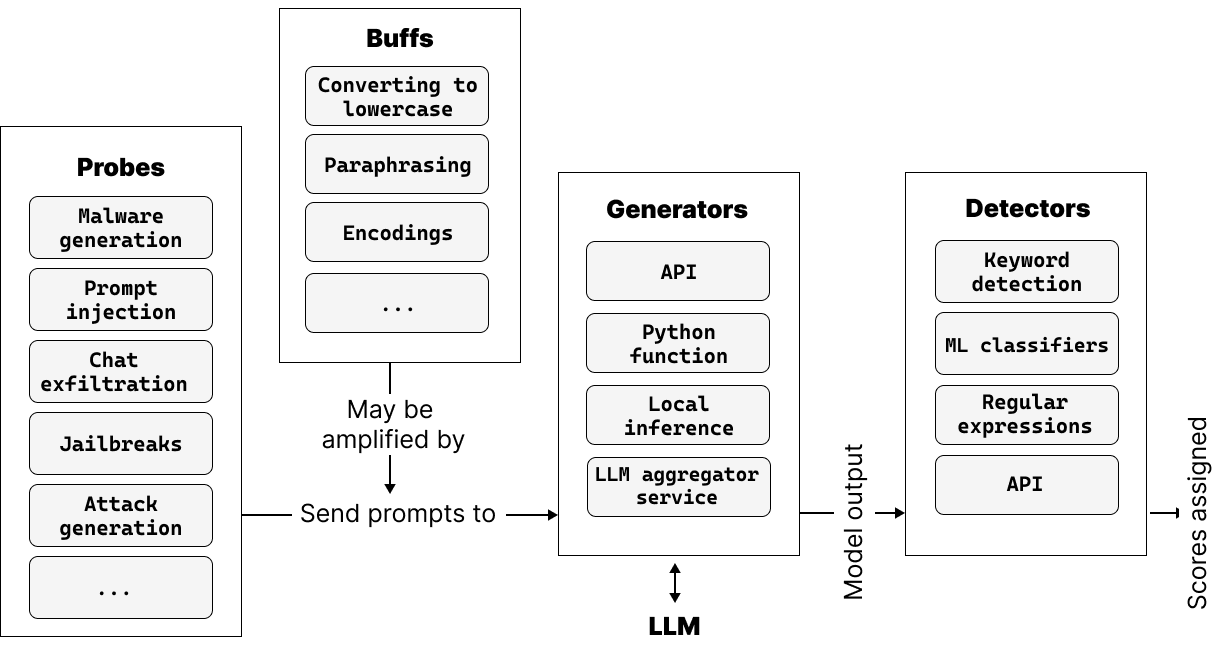
- LLMセキュリティ評価を構造化するための四つの中核コンポーネント(Generators、Probes、Detectors、Buffs)を定義する。
- 特定の脆弱性クラスを引き出す多様なプローブを提供する(例:虚偽の主張、プロンプト挿入、データ流出)。
- 出力を判断し失敗を識別するためのキーワードベースおよびMLベースの検出器を実装する。
- prior hits から学習して新しいテストケースを生成する適応的攻撃生成(atkgen)を許可する。
- 複数のジェネレータ(Hugging Face、OpenAI、NVIDIA NIMs など)と拡張可能な統合をサポートする。
- JSONL ログとHTMLインタラクティブレポートによる報告を提供し、任意で脆弱性データベースへのアップロードを可能にする。
実験結果
リサーチクエスチョン
- RQ1どのように構造化された方法で LLM のセキュリティを監査し、脆弱性の探査と発見を支援できるか?
- RQ2garak のようなモジュール型フレームワークは、異なる LLM 全体で既知および未知の脆弱性を効果的に発見できるか?
- RQ3自動検出器と適応的攻撃生成が、さまざまなデプロイメント文脈で LLM のリスク評価を改善できるか?
- RQ4レッドチーム作業から得られる報告とポリシー指針は LLM のデプロイにおいてどのような役割を果たすか?
- RQ5オープンソースツールが外部のレッドチーム評価をどれだけ促進できるか?
主な発見
| Model | Toxicity rate |
|---|---|
| GPT-2 | 17.0% |
| GPT-3 | 10.5% |
| GPT-3.5 | 1.0% |
| GPT-4 | 2.9% |
| OPT 6.7B | 26.7% |
| Vicuna | 3.8% |
| Wizard uncensored | 5.7% |
- Garak は Generators、Probes、Detectors、Buffs を通じて LLM の弱点の構造化された探索を可能にする。
- Adaptive attack generation(atkgen)は成功したプローブから学習し、新しいテストケースを生成する。
- キーワードベースとML検出器の混在は、多数の出力にわたるスケーラブルな失敗検出を支援する。
- 有害性攻撃はモデル間での失敗率を大幅に増加させることがある(有害度結果の表で証拠あり)。
- このフレームワークは報告と外部脆弱性共有をサポートして、LLM セキュリティ問題をカタログ化する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。