[論文レビュー] Gemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations
本論文は、医療推論、幻覚リスク(Med-HALT)、医療VQAにおいて、MultiMedQA、Med-HALT、NEJM-VQAベンチマークを用いて、オープンソースと商用の医療LLMに対してGoogle Geminiを評価し、プロンプティング戦略と評価ツールを提供する。Geminiは複数の医療タスクでMed-PaLM 2およびGPT-4に遅れ、顕著な幻覚リスクを示す一方、プロンプティング技術で改善を見せる。
Large language models have the potential to be valuable in the healthcare industry, but it's crucial to verify their safety and effectiveness through rigorous evaluation. For this purpose, we comprehensively evaluated both open-source LLMs and Google's new multimodal LLM called Gemini across Medical reasoning, hallucination detection, and Medical Visual Question Answering tasks. While Gemini showed competence, it lagged behind state-of-the-art models like MedPaLM 2 and GPT-4 in diagnostic accuracy. Additionally, Gemini achieved an accuracy of 61.45\% on the medical VQA dataset, significantly lower than GPT-4V's score of 88\%. Our analysis revealed that Gemini is highly susceptible to hallucinations, overconfidence, and knowledge gaps, which indicate risks if deployed uncritically. We also performed a detailed analysis by medical subject and test type, providing actionable feedback for developers and clinicians. To mitigate risks, we applied prompting strategies that improved performance. Additionally, we facilitated future research and development by releasing a Python module for medical LLM evaluation and establishing a dedicated leaderboard on Hugging Face for medical domain LLMs. Python module can be found at https://github.com/promptslab/RosettaEval
研究の動機と目的
- Geminiの医療推論能力をテキストおよび視覚モダリティで評価する。
- 医療文脈におけるGeminiの幻覚傾向と安全性リスクを定量化する。
- 医療ベンチマークでGeminiをオープンソースLLMと商用モデルと比較する。
- プロンプティング戦略とモデル改善のための実用的なフィードバックを提供する。
- 再現性のある研究を促進するための評価ツールと医療ドメインのリーダーボードを公開する。
提案手法
- deterministic設定(温度0.0、top-p1.0)でGemini Pro開発者APIを用いて評価する。
- プロンプティング技法(ゼロショット、few-shot、連鎖思考、自己整合性、アンサンブル精煉)を用いてMultiMedQA、Med-HALT、Medical Visual Question Answeringをベンチマークする。
- オープンソースLLM(Llama系、Mistral、Yi-34b、Qwen-72b等)およびクローズドモデル(MedPaLM、MedPaLM 2、GPT-4)と比較する。
- MultiMedQAとVQA全体で正確性を主要指標とし、Med-HALT評価にはPointwise Scoreを使用する。
- 医療LLM評価用のRosettaEval Pythonモジュールと医療LLM用のHugging Faceリーダーボードを導入する。
実験結果
リサーチクエスチョン
- RQ1Geminiはテキストと画像を横断した複雑な医療推論問題をどれだけ正確に解けるのか?
- RQ2Geminiは医療回答に幻覚や過信を示すのか?
- RQ3標準ベンチマークでGeminiの性能はオープンソースおよび商用の医療LLMとどう比べるのか?
- RQ4Geminiの医療推論を改善し幻覚を減らすのに有効なプロンプティング戦略は何か?
- RQ5Geminiの医療知識と多模態能力にはドメイン特有の強みと弱みがどこにあるのか?
主な発見
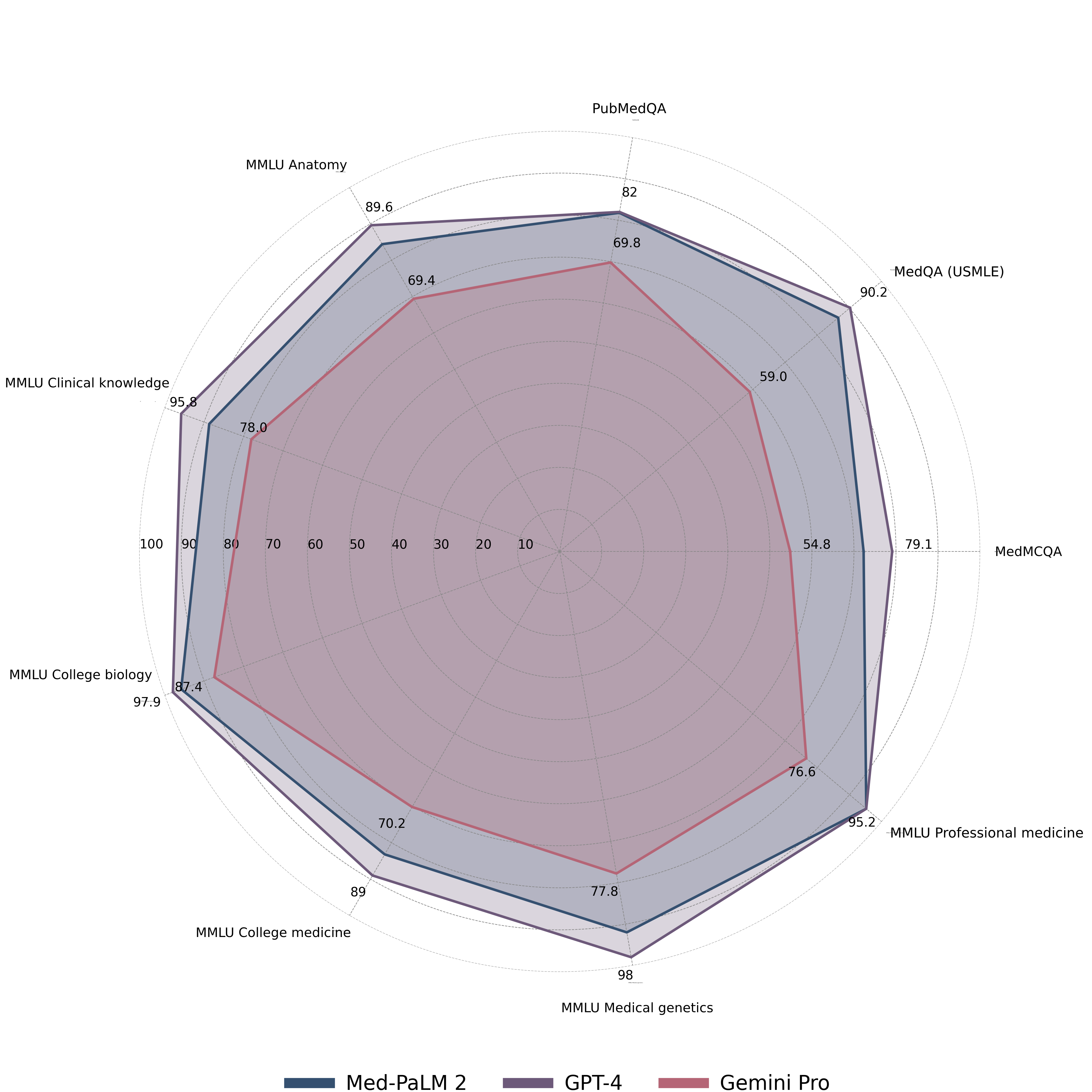
- Gemini ProはMultiMedQAベンチマークで強力だが、Med-PaLM 2とGPT-4には及ばない(例:MedQA USMLEおよびMedMCQAの結果について言及)。
- Med-HALTではReasoning Fakeに対する高精度を示す一方、過信の回避(Reasoning FCT)とメモリベースの検索課題(IR PubMedlinkタスク)には保護が低い。
- Medical VQAのGemini Proの正解率は61.45%、GPT-4Vの88%には大きく及ばない。
- 主題別分析ではGeminiはBiostatistics、Epidemiology、Cell Biology、および消化器・産婦婦などの特定領域で優れる一方、他の医療サブ分野や複雑な推論タスクでは劣る。
- Chain-of-ThoughtやEnsemble Refinementといったプロンプティング戦略は特定領域での性能を改善できるが、データセットにより効果は異なる。ゼロショットとFew-shotプロンプトはタスクごとに異なる利得をもたらす。
- 著者らはPython評価モジュール(RosettaEval)を提供し、再現可能な医療LLM研究を支援するHugging Faceリーダーボードを確立している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。