[論文レビュー] Generative AI for Medical Imaging: extending the MONAI Framework
この論文は MONAI Generative Models を提示します。これは MONAI を拡張して、2D/3Dモダリティ全体で拡散、トランスフォーマー、GANs といった多様な医用画像生成モデルを学習・評価・デプロイするオープンソースプラットフォームです。事前学習済みモデルとモジュール化されたコンポーネントを提供します。
Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.
研究の動機と目的
- プライバシー保護されたデータ共有と多様な医用画像タスクを促進するための生成AIの活用を動機づける。
- 医用画像生成モデルを学習・評価・デプロイする標準化されたモジュール型プラットフォームを提供する。
- クロスモダリティとクロスデータセット適用性を示す(CT、MRI、X-ray;2D/3D)。
- 再現性と最先端手法との比較を簡素化する事前学習済みモデルとコンポーネントを提供する。
提案手法
- Timesteps conditioning と空間トランスフォーマを条件情報として用いた DiffusionModelUNet を実装。
- DDIMScheduler と PNDMScheduler および複数のノイズプロファイル(linear, scaled linear, cosine)を備えた Scheduler 抽象化を導入。
- 潜在空間生成のため AutoencoderKL と VQVAE を用いた latent diffusion models をサポート。
- ControlNets および PatchDiscriminator のバリアント(PatchDiscriminator, MultiScalePatchDiscriminator)を組み込み、条件付けと敵対的学習を実現。
- autoregressive transformers と Ordering クラスを提供して高次元データを 1D トランスフォーマへ適用。
- SPADE に類似した適応正規化を画像合成に統合し、敵対的コンポーネントと組み合わせる。
- loss 関数(スペクトral losses、patch-based adversarial loss、perceptual losses)と MONAI-pretrained networks(2D RadImageNet、3D MedicalNet)を含む。
- 評価指標(FID、MMD、MS-SSIM)と 2.5D アプローチを用いた3D知覚損失で計算量のバランスを取る。
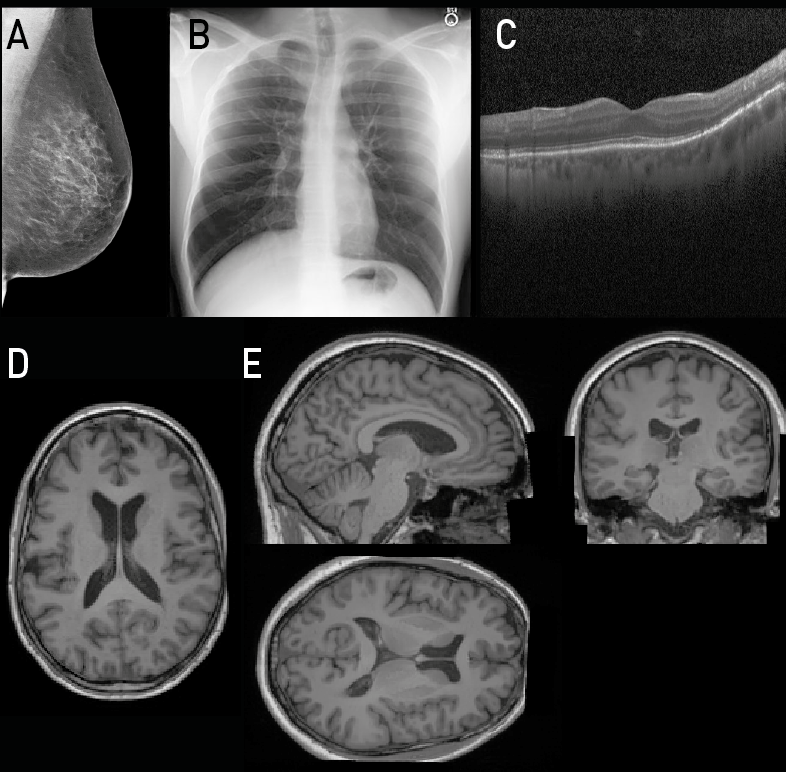
実験結果
リサーチクエスチョン
- RQ1MONAI Generative Models は Diffusion、transformers、GANs といった最先端生成手法を医用画像領域で統一的な MONAI フレームワーク内で再現・拡張できるか。
- RQ2これらのモデルは 2D/3D 医用データと複数モダリティ(CT、MRI、X-ray)および解剖領域に跨って一般化可能か。
- RQ3テキストプロンプトやセマンティックレイアウトといった conditioning シグナルは生成画像の忠実度と参照画像との整合性にどう影響するか。
- RQ4圧縮(VQ-VAE、AutoencoderKL)と生成コンポーネント(diffusion、transformer)のモジュール性・交換性はプラットフォーム内でどの程度実現可能か。
- RQ5プラットフォームはアウトオブディストリビューション検出、画像翻訳、医用画像の超解像といった下流タスクをサポートできるか。
主な発見
| データセット | データタイプ | 次元 | FID | MS-SSIM | MS-SSIM 再構成 |
|---|---|---|---|---|---|
| MIMIC-CXR | 2D Chest X-ray | 512×512 | 8.8325 | 0.4276 | 0.9834 |
| CSAW-M | 2D Mammography | 640×512 | 1.9061 | 0.5356 | 0.9789 |
| Retinal OCT | 2D OCT | 512×512 | 2.2501 | 0.3593 | 0.8966 |
| UK Biobank | 2D Brain Slice MRI | 160×224 | 2.1986 | 0.5368 | 0.9876 |
| UK Biobank | 3D Brain MRI | 160×224×160 | 0.0051 | 0.9217 | 0.9820 |
- 多様なデータセット(MIMIC-CXR、CSAW-M、UK Biobank、retinal OCT)で学習した latent diffusion models は2Dおよび3Dデータで高品質・多様なサンプルを生み出す。
- FID スコアはデータセット間で低〜中程度の範囲(例: 3D UK Biobank brain MRI で 0.0051、CSAW-M で 1.9061)で、MS-SSIM 再構成は忠実な再構成を示す(例: 3D Brain MRI で 0.9820)。
- テキストプロンプトによる条件付きサンプリングは高い CLIP アラインメント(BiomedCLIP)を達成しつつ FID を適度に維持し、生成をコントロール可能である。
- モジュール性: VQ-VAE + Transformer および VQ-VAE + Diffusion Model バリアントは MIMIC-CXR で競合的な FID を示し、潜在生成バックボーンの交換性を示す(9.1995 対 8.0457)。
- デモにはアウトオブディストリビューション検出(Decathlon データセット横断で Transformer ベース手法の AUC が 1.0 として報告)や画像翻訳(FLAIR から T1-weighted MRI)、高忠実度指標(PSNR、MAE、MS-SSIM)を含む。
- カスケード Diffusion アプローチによる画像超解像は 3D データで高い忠実度と多様性を実現(FID がほぼ0、PSNR 約 29.8、MS-SSIM 約 0.98)。
![Figure 2: CLIP Score vs FID Pareto curve for the LDM trained on chest X-Ray data. We sweep over guidance values of [1, 1.5, 1.75, 2, 3, 4, 5, 6, 7, 8, 9, 10]](https://ar5iv.labs.arxiv.org/html/2307.15208/assets/figures/fid_vs_clip_score.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。