[論文レビュー] Generative AI for Synthetic Data Generation: Methods, Challenges and the Future
本論文は、巨大で固定されたLLMがどのようにタスク特異的な合成データを生成できるかを概説し、 promptingと適応手法をレビュー、データ品質を評価し、応用と課題と今後の方向性を論じる。
The recent surge in research focused on generating synthetic data from large language models (LLMs), especially for scenarios with limited data availability, marks a notable shift in Generative Artificial Intelligence (AI). Their ability to perform comparably to real-world data positions this approach as a compelling solution to low-resource challenges. This paper delves into advanced technologies that leverage these gigantic LLMs for the generation of task-specific training data. We outline methodologies, evaluation techniques, and practical applications, discuss the current limitations, and suggest potential pathways for future research.
研究の動機と目的
- 専門分野でのデータ不足とプライバシーの問題に対処するため、合成データ生成の動機付けを行う。
- モデルを再訓練せずに、巨大な固定LLMがタスク特異的な訓練データを生成できる方法を検討する。
- データ生成手法、品質評価、および下流の学習戦略を要約する。
- 実用的な応用を議論し、今後の研究方向と未解決の課題を概説する。
提案手法
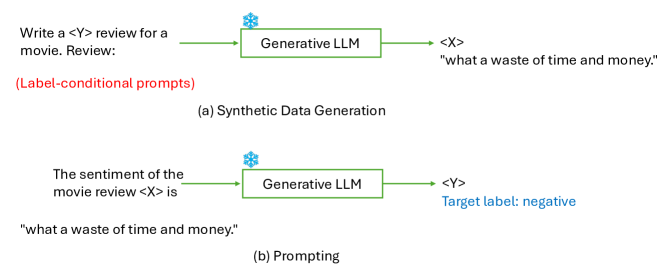
- 属性制御プロンプトやヴァーバライザーを含む、タスク条件付きデータ生成のプロンプトエンジニアリング技術を説明する。
- データ生成のためにLLMsを適用するためのパラメータ効率の良いタスク適応手法(例:アダプター、プレフィックス/プロンプト微調整、LoRA)を検討する。
- 多様性、正確性、自然さといったデータ品質測定アプローチと品質推定パイプラインを説明する。
- 正則化やサンプル重み付けスキームを含む、合成データを効果的に活用するための訓練戦略を概説する。
- データ生成手法の分類を提供し、NLPにおける代表的なシステムとベンチマークを要約する。
実験結果
リサーチクエスチョン
- RQ1再訓練せずにLLMからタスク特異的な合成データを生成する主な方法は何か?
- RQ2下流訓練のために合成データの品質をどのように測定し保証できるか?
- RQ3リソースの乏しい分野や機微な分野における合成データの実用的な応用とデプロイの考慮事項は何か?
- RQ4生成的LLMからの合成データの利用を形作る課題と今後の方向性は何か?
主な発見
- NLPタスクのためのラベル付きまたはラベルなしの合成データを生成する、ZeroGen、ProGen、MSP、FewGen など、いくつかのデータ生成手法が出現している。
- 合成データの品質は多様性、正確性、自然さに沿って評価され、正確性には自動評価と人間評価が用いられる。
- プロンプトエンジニアリングと属性制御プロンプトは、生成データの関連性と多様性を向上させる。
- パラメータ効率的な適応により、完全なモデル微調整なしにタスク特異的なデータ生成を可能にする。
- 合成データは、医療や教育分野を含む低資源・高速推論シナリオに有望だが、幻覚やプライバシー懸念といった課題に直面している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。