[論文レビュー] Generative AI on the Edge: Architecture and Performance Evaluation
この論文は、CPUのみの Raspberry Pi エッジクラスタ上で K3s 管理の Docker ベースのセットアップを用い、スループット、待機時間、メモリ/CPU 使用量、精度を定量化して、クラウド依存なしの GenAI のエッジでの実現性を評価する。
6G's AI native vision of embedding advance intelligence in the network while bringing it closer to the user requires a systematic evaluation of Generative AI (GenAI) models on edge devices. Rapidly emerging solutions based on Open RAN (ORAN) and Network-in-a-Box strongly advocate the use of low-cost, off-the-shelf components for simpler and efficient deployment, e.g., in provisioning rural connectivity. In this context, conceptual architecture, hardware testbeds and precise performance quantification of Large Language Models (LLMs) on off-the-shelf edge devices remains largely unexplored. This research investigates computationally demanding LLM inference on a single commodity Raspberry Pi serving as an edge testbed for ORAN. We investigate various LLMs, including small, medium and large models, on a Raspberry Pi 5 Cluster using a lightweight Kubernetes distribution (K3s) with modular prompting implementation. We study its feasibility and limitations by analyzing throughput, latency, accuracy and efficiency. Our findings indicate that CPU-only deployment of lightweight models, such as Yi, Phi, and Llama3, can effectively support edge applications, achieving a generation throughput of 5 to 12 tokens per second with less than 50\% CPU and RAM usage. We conclude that GenAI on the edge offers localized inference in remote or bandwidth-constrained environments in 6G networks without reliance on cloud infrastructure.
研究の動機と目的
- 6G/ORAN コンテキストでリソース制約のあるエッジデバイス上で Generative AI を動作させる実現性を動機づけ、定量化する。
- エッジハードウェア上でのモデルサイズ(大・中・小)と量子化(4-bit GGUF)がスループット、待機時間、メモリ、CPU 使用量、精度に与える影響を評価する。
- 将来のネットワークエッジでの GenAI 実験のための拡張可能なエッジ AI テストベッドと手法を提供する。
- エッジ展開のモデルと設定を経験的結果に基づいて選択する具体的な指針を提供する。
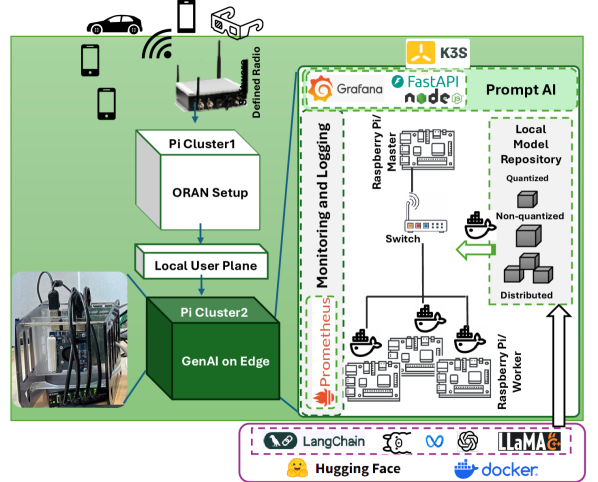
提案手法
- K3s(軽量Kubernetes)で調整された four Raspberry Pi 5 ノードからなるエッジテストベッド。
- モジュール型 API ベースのアーキテクチャを持つ Docker 化された PromptAI サービス。
- Hugging Face からの Docker ベースのワークフローを介してデプロイされる 4-bit GGUF モデルの量子化。
- メモリ、CPU、遅延、精度、スループットを測定するために、OpenAssistant/oasst1 プロンプトのサブセット(50 ダイアログ、5回以上のターン)を評価。
- 性能分析は llama.cpp フレームワークを用いた決定論的推論を前提とし、各プロンプトあたり最大 500 トークンを生成。
実験結果
リサーチクエスチョン
- RQ1CPU のみのエッジデバイス(Raspberry Pi クラスター)で対話型AIタスクの推論を効果的に実行できるか?
- RQ2モデルサイズ(大・中・小)と量子化(4-bit GGUF)がエッジハードウェアのスループット、待機時間、メモリ、CPU、精度にどのような影響を与えるか?
- RQ3実時間対話シナリオにおけるエッジ展開LLMの安定性と文脈感度の特徴は?
- RQ4スケーラブルでモジュラーなエッジ GenAI 実験を支えるデプロイ構成とツール(K3s、Docker、PromptAI)はどれが最適か?
主な発見
- 軽量モデル(Yi、Phi)は CPU 上で実用的なスループットと待機時間を達成し、生成はおおよそ 5–12 トークン/秒、CPUと RAM 使用率は 50% 未満。
- エンドツーエンドの待機時間とスループットはモデルサイズにより異なる。Yi のような小型モデルは Total time per token が InternLM よりも圧倒的に速い一方、より大きなモデルは待機時間の代償として精度が向上。
- メモリ使用量は一般にモデルサイズとともに増加(InternLM、Mistral、Llama2 は 0.66–3.14 GB 以上)、CPU 使用量はほぼ全モデルで約 50%程度。
- Winogrande ベンチマークでの精度はモデルごとに異なり、InternLM は ~0.8、Gemma は ~0.7、Llama3 は ~0.69、一方で Yi と Zephyr はそれぞれ ~0.49 と ~0.46(非ファインチューニング済み)。
- スループットの時系列分析ではコンテキスト長の感度がモデル間で異なる;Mistral、InternLM はプロンプト長の変化に対して安定している一方、Llama3、Phi、Yi は Prefill/Decode フェーズでより変動を示す。
- システムはデプロイ中にメモリエラーや再起動がなく頑健であり、量子化はメモリ使用量を減らす一方で一部の精度低下を受け入れる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。