[論文レビュー] Generative Sequential Recommendation with GPTRec
GPTRec は SVD ベースのサブアイテムトークン化を用いてメモリを削減する GPT-2 に基づく逐次生成型推薦システムで、Next-K生成を導入し、ランキングは SASRec に匹敵する一方でメモリ効率と柔軟な生成を実現します。
Sequential recommendation is an important recommendation task that aims to predict the next item in a sequence. Recently, adaptations of language models, particularly Transformer-based models such as SASRec and BERT4Rec, have achieved state-of-the-art results in sequential recommendation. In these models, item ids replace tokens in the original language models. However, this approach has limitations. First, the vocabulary of item ids may be many times larger than in language models. Second, the classical Top-K recommendation approach used by these models may not be optimal for complex recommendation objectives, including auxiliary objectives such as diversity, coverage or coherence. Recent progress in generative language models inspires us to revisit generative approaches to address these challenges. This paper presents the GPTRec sequential recommendation model, which is based on the GPT-2 architecture. GPTRec can address large vocabulary issues by splitting item ids into sub-id tokens using a novel SVD Tokenisation algorithm based on quantised item embeddings from an SVD decomposition of the user-item interaction matrix. The paper also presents a novel Next-K recommendation strategy, which generates recommendations item-by-item, considering already recommended items. The Next-K strategy can be used for producing complex interdependent recommendation lists. We experiment with GPTRec on the MovieLens-1M dataset and show that using sub-item tokenisation GPTRec can match the quality of SASRec while reducing the embedding table by 40%. We also show that the recommendations generated by GPTRec on MovieLens-1M using the Next-K recommendation strategy match the quality of SASRec in terms of NDCG@10, meaning that the model can serve as a strong starting point for future research.
研究の動機と目的
- 逐次推薦にジェネレーティブモデルの利用を促し、大規模アイテム語彙と Top-K を超える柔軟な目的に対応する。
- アイテムIDをサブアイテムトークンに分割するためのSVDを用いたメモリ効率の高いトークン化を導入する。
- 相互依存的な推薦リストと複雑な目的を可能にする Next-K Generation 戦略を提案する。
- GPTRec アーキテクチャを GPT-2 に基づいて、MovieLens-1M で SASRec および BERT4Rec と比較する。
提案手法
- アイテムトークンの系列モデリングにクロスエントロピー損失を用いた GPT-2 デコーダーアーキテクチャを採用する。
- ユーザー–アイテム行列の量子化された SVD 埋め込みから各アイテムにつき t 個のサブアイテムトークンを作成する SVD トークン化を導入する。
- 1 トークン per item と 1 アイテムあたり複数トークンのモードを許可し、メモリ使用と生成のバランスを取る。
- Next-K の生成を含む Top-K および Next-K 生成戦略を実装し、Next-K の生成ごとのスコアリングを導入する。
- Leave-one-out セットアップと最大シーケンス長 100 の3 層 Transformer を用いて MovieLens-1M で評価する。
- GPTRec のバリアント(GPTRec-TopK、GPTRec-NextK)を SASRec および BERT4Rec と Recall@10 および NDCG@10で比較する。
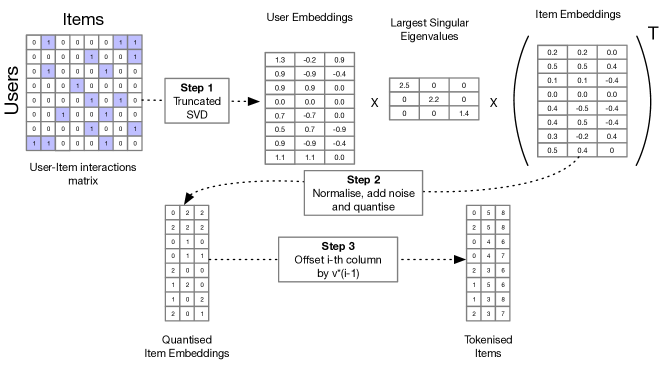
実験結果
リサーチクエスチョン
- RQ1GPTRec は1 トークン-per-id モードで BERT4Rec および SASRec と比較してどうか。
- RQ2GPTRec のマルチトークン-アイテムモードにおけるトークン数とトークンあたりの値の数の影響は何か。
- RQ3Next-K 推薦モードにおけるカットオフレベル K が GPTRec の性能に与える影響は何か。
主な発見
| Model name | Generation Strategy | Architecture | Training Task | Loss | Recall@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| BERT4Rec | TopK | Encoder | MLM (Item Masking) | Cross Entropy (Softmax Loss) | 0.282 | 0.152 |
| GPTRec-TopK | TopK | Decoder | LM (Sequence Shifting) | Cross Entropy (Softmax Loss) | 0.254 | 0.146 |
| SASRec | TopK | Decoder | LM (Sequence Shifting) | Binary Cross-Entropy | 0.199 | 0.108 |
| GPTRec-NextK | NextK | Decoder | LM (Sequence Shifting) | Cross Entropy (Softmax Loss) | 0.157 | 0.105 |
- GPTRec-NextK は MovieLens-1M で Recall@10 = 0.157, NDCG@10 = 0.105 を達成し、Recall@10 = 0.199、NDCG@10 = 0.108 の SASRec と競合する。
- GPTRec-TopK は Recall@10 = 0.254, NDCG@10 = 0.146 を達成し、Top-K 設定でこれらの指標で SASRec を上回る。
- BERT4Rec は Recall@10 = 0.282, NDCG@10 = 0.152 で、報告された表の GPTRec 系列より高い。
- SVD トークン化は埋め込みメモリ使用を劇的に削減する(例: t=8, v=2048 は 16 MB、1 トークン-per-item の場合は一部の規模で 10 GB を超える)。
- Next-K モードの GPTRec は、複雑な目的に対応しつつ競争力のあるランキング品質を維持できる柔軟な生成フレームワークを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。