[論文レビュー] Ghostbuster: Detecting Text Ghostwritten by Large Language Models
Ghostbuster は、ターゲットモデルの確率を必要とせず、弱い言語モデル上の構造化特徴探索とロジスティック分類器を用いて AI生成テキストを検出し、ドメイン間でイン-domain の F1 が 99.0 を達成します。
We introduce Ghostbuster, a state-of-the-art system for detecting AI-generated text. Our method works by passing documents through a series of weaker language models, running a structured search over possible combinations of their features, and then training a classifier on the selected features to predict whether documents are AI-generated. Crucially, Ghostbuster does not require access to token probabilities from the target model, making it useful for detecting text generated by black-box models or unknown model versions. In conjunction with our model, we release three new datasets of human- and AI-generated text as detection benchmarks in the domains of student essays, creative writing, and news articles. We compare Ghostbuster to a variety of existing detectors, including DetectGPT and GPTZero, as well as a new RoBERTa baseline. Ghostbuster achieves 99.0 F1 when evaluated across domains, which is 5.9 F1 higher than the best preexisting model. It also outperforms all previous approaches in generalization across writing domains (+7.5 F1), prompting strategies (+2.1 F1), and language models (+4.4 F1). We also analyze the robustness of our system to a variety of perturbations and paraphrasing attacks and evaluate its performance on documents written by non-native English speakers.
研究の動機と目的
- ドメイン、プロンプト、モデルを超えた強い汎化性能を持つ堅牢な AI生成テキスト検出器の必要性を動機づける。
- ターゲットモデルのトークン確率へのアクセスを必要としない検出手法を開発する(ブラックボックス設定)。
- 検出器を評価するため、ドメイン横断のベンチマークを作成・公開する(学生のエッセイ、ニュース、創作など)。
- 汎化、促し戦略への頑健性、およびモデルパラダイムの変化を調査する。
- 崩れにくさを低減する解釈可能な特徴中心の検出アプローチを提供する。
提案手法
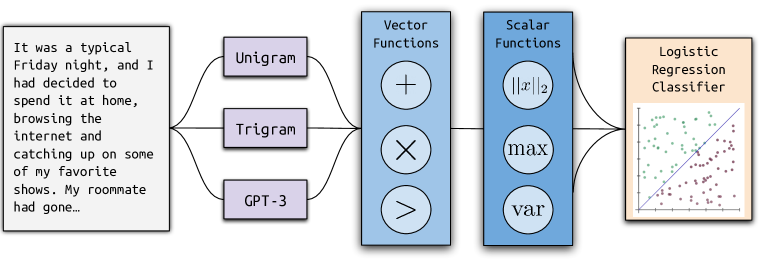
- 各文書を一連の弱い言語モデルに通して、トークンごとの確率を得る。
- モデル確率を組み合わせるベクトル/スカラー特徴関数の空間に対して構造化探索を定義する。
- 選択された特徴と7つの手作り特徴を用いてロジスティック回帰分類器を訓練する。
- 弱いモデル(Unigram、Kneser–Ney のトライグラム、ada、davinci)の確率ベクトルを特徴構築の入力として用いる。
- 分布シフトに対する頑健性を高めるため、高容量の順序モデルへの依存を避ける。
実験結果
リサーチクエスチョン
- RQ1ターゲットモデルのトークン確率へのアクセスなしで AI生成テキストを検出できるか(ブラックボックス検出)?
- RQ2検出器はドメイン、プロンプト、未知のモデルに対してどの程度汎化するか?
- RQ3構造化特徴と弱いモデルの確率アプローチは、編集や言い換えに対して頑健か?
- RQ4文書長が検出性能に与える影響は?
- RQ5非英語ネイティブテキストでの性能は?
主な発見
- Ghostbuster は3つのドメインにわたるイン-domain 検出で 99.0 F1 を達成。
- アウト・オブ・ドメイン平均 F1 は 97.0、DetectGPT を 39.6、GPTZero を 7.5 上回る。
- プロンプト間の汎化は 99.5 F1、RoBERTa および GPTZero より良い。
- Claude を含むモデル間で、Ghostbuster は Claude で 92.2 F1、ChatGPT ベースのデータと比べて劣化がある。
- アブレーションは、構造化探索とニューラルLM確率(ada, davinci)の含有が性能に不可欠であることを示し、手作り特徴のみの影響は限定的。
- 長い文書で性能が向上し、非常に短いテキスト(≤100トークン)では信頼性が低い。
- ベンチマーク用のコードと新しいデータセット3つを公開。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。