[論文レビュー] Gorilla: Large Language Model Connected with Massive APIs
Gorillaはretrievalを用いて大規模なML APIの呼び出しを可能にするようファインチューニングされたLLaMA-7Bモデルで、GPT-4より高いAPI呼び出し精度と低い幻覚を達成し、retriever-aware trainingを通じてテスト時のAPI変更に適応する。
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today's state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call. We release Gorilla, a finetuned LLaMA-based model that surpasses the performance of GPT-4 on writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible user updates or version changes. It also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly. To evaluate the model's ability, we introduce APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs. Gorilla's code, model, data, and demo are available at https://gorilla.cs.berkeley.edu
研究の動機と目的
- LLMがファインチューニングとretrievalを通じて、大規模で変化するAPI空間を利用できるよう動機づける。
- APIBenchを作成・活用してAPI呼び出しの正確さと幻覚をベンチマークする。
- APIドキュメントの更新に適応するretriever-awareなトレーニングパイプラインを開発する。
- 制約と複数のretrieverがAPI呼び出しの品質と信頼性に与える影響を評価する。)
- method:[
- Construct APIBench by collecting 1,645 API calls from TorchHub, TensorHub, and HuggingFace model hubs and generating 10 instruction–API pairs per API.
- Fine-tune a LLaMA-7B base model with instruction-tuning to specialize in API call generation.
- Incorporate a document retriever into training and inference to provide up-to-date API documentation in prompts (retriever-aware training).
- Evaluate API-call accuracy using an AST-based sub-tree matching to verify functional correctness of generated API calls and identify hallucinations.
- Support two inference modes: zero-shot (no retriever) and retrieval (use retrieved API docs).
- Analyze constraints-aware API invocations (e.g., accuracy, parameter count) to study trade-offs when selecting APIs.
提案手法
- 0
- 0
![Figure 1: Examples of API calls . Example API calls generated by GPT-4 [ 29 ] , Claude [ 3 ] , and Gorilla for the given prompt. In this example, GPT-4 presents a model that doesn’t exist, and Claude picks an incorrect library. In contrast, our Gorilla model can identify the task correctly and sugge](https://ar5iv.labs.arxiv.org/html/2305.15334/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1How accurately can an LLM generate correct, executable API calls from natural language prompts when faced with a large, overlapping, and changing API space?
- RQ2Does adding a retriever to fine-tune/infer improve API-call correctness and reduce hallucinations, especially under test-time documentation changes?
- RQ3Can the model reason about API usage constraints and select APIs that satisfy given requirements?
- RQ4How does Gorilla compare to existing state-of-the-art LLMs (GPT-4, Claude, etc.) on API-call tasks across multiple API hubs?
主な発見
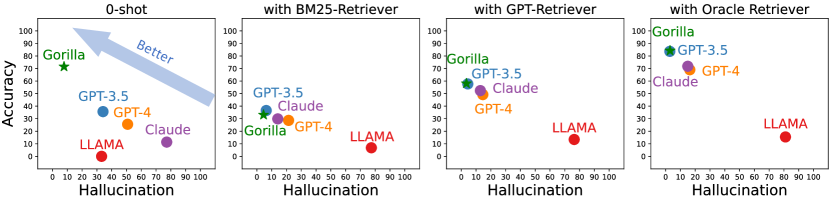
- Gorilla significantly outperforms GPT-4 in API-functionality accuracy and reduces hallucinations across TorchHub and HuggingFace; it matches GPT-4 on TensorFlow Hub.
- Lightly finetuned Gorilla achieved state-of-the-art zero-shot performance, about 20.43% better than GPT-4 and 10.75% better than ChatGPT across evaluated datasets.
- Retrieval-aware training improves adaptation to test-time API documentation changes and reduces hallucination compared with non-retrieval baselines, though non-optimal retrievers can sometimes hurt performance.
- Finetuning with a ground-truth retriever yields substantial gains (e.g., ~12.37% improvement in TorchHub and ~23.46% in HuggingFace) compared to training without a retriever, though evaluation-time retrievers may still incur degradation.
- The study demonstrates Gorilla’s ability to understand and apply API constraints (e.g., selecting models with required accuracy and parameter bounds) and to adapt to documentation updates without retraining.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。