[論文レビュー] GPT-4 as an Agronomist Assistant? Answering Agriculture Exams Using Large Language Models
本論文は、CCA、Embrapa、AgriExamsデータセットの農業質問に対してGPT-4、GPT-3.5、Llamaモデルを評価し、RAGとEnsemble Refinementを用いて性能を向上させ、GPT-4が最高の精度を達成し、農学の試験に合格する可能性を示す。
Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding across various domains, including healthcare and finance. For some tasks, LLMs achieve similar or better performance than trained human beings, therefore it is reasonable to employ human exams (e.g., certification tests) to assess the performance of LLMs. We present a comprehensive evaluation of popular LLMs, such as Llama 2 and GPT, on their ability to answer agriculture-related questions. In our evaluation, we also employ RAG (Retrieval-Augmented Generation) and ER (Ensemble Refinement) techniques, which combine information retrieval, generation capabilities, and prompting strategies to improve the LLMs' performance. To demonstrate the capabilities of LLMs, we selected agriculture exams and benchmark datasets from three of the largest agriculture producer countries: Brazil, India, and the USA. Our analysis highlights GPT-4's ability to achieve a passing score on exams to earn credits for renewing agronomist certifications, answering 93% of the questions correctly and outperforming earlier general-purpose models, which achieved 88% accuracy. On one of our experiments, GPT-4 obtained the highest performance when compared to human subjects. This performance suggests that GPT-4 could potentially pass on major graduate education admission tests or even earn credits for renewing agronomy certificates. We also explore the models' capacity to address general agriculture-related questions and generate crop management guidelines for Brazilian and Indian farmers, utilizing robust datasets from the Brazilian Agency of Agriculture (Embrapa) and graduate program exams from India. The results suggest that GPT-4, ER, and RAG can contribute meaningfully to agricultural education, assessment, and crop management practice, offering valuable insights to farmers and agricultural professionals.
研究の動機と目的
- 主要な生産国(米国、ブラジル、インド)からの農業関連質問に対して、LLMsの能力を評価する。
- retrieval Augmented Generation (RAG)とEnsemble Refinement (ER)がモデル性能に与える影響を調査する。
- GPT-4が農学認証系の試験に合格する可能性と作物管理の指針を提供する潜在性を探る。
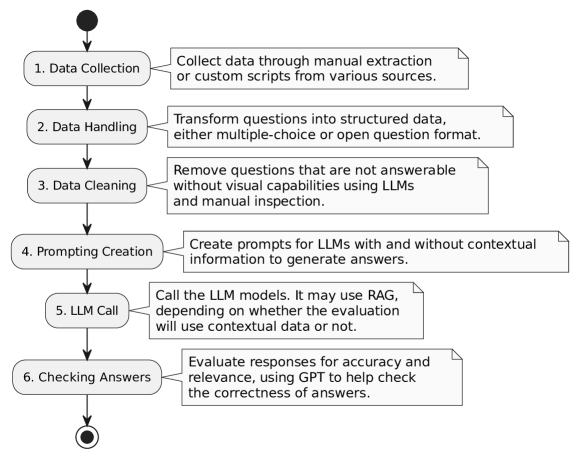
提案手法
- CCA、Embrapa、AgriExamsデータセットからドメイン特化の質問を収集・整理する。
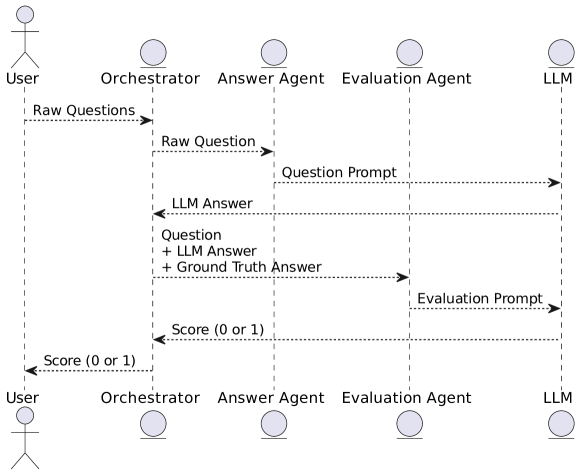
- 文脈提供と二-agent(Answer、Evaluation)セットアップをオーケストレーターによって統括するプロンプト設計を適用する。
- RAGとERの技術を用いて回答を強化し、USA/インドデータセットの文脈にはLlama Indexを利用する。
- 専用の評価プロンプトとスコアリング機構を用いて回答を正解と比較して評価する。
- RAG/ER/プレアンブルの有無を問わず、複数モデル(Llama2-13B, Llama2-70B, GPT-3.5, GPT-4)をシナリオごとに比較する。
- 精度向上と計算コストのトレードオフを分析する。
実験結果
リサーチクエスチョン
- RQ1GPT-4、GPT-3.5、Llamaモデルは、多様なデータセット(CCA、Embrapa、AgriExams)からの農業関連質問にどれくらい正確に答えられるか?
- RQ2農業QAタスクにおけるretrieval(RAG)とensemble refinement(ER)のモデル精度への影響は?
- RQ3LLMは農学認証風の試験に合格し、実用的な作物管理指針を提供できるか?
- RQ4文脈提供(プレアンブル、Llama Index)は、ドメイン特化の農業質問に対するモデル性能にどう影響するか?
主な発見
| シナリオ | RAG | ER | プレアンブル | Llama2-13B | Llama2-70B | GPT-3.5 | GPT-4 |
|---|---|---|---|---|---|---|---|
| 1 | 47% | 55% | 64% | 79% | |||
| 2 | 48% | 60% | 66% | 82% | |||
| 3 | RAG | 92% | 93% | ||||
| 4 | RAG | ER | 70% | 81% | 82% | 93% | |
| 5 | RAG | ER | 71% | 81% | 88% | 93% |
- GPT-4は、テストされたモデルの中で、動画ベースおよびテキストベースの農業質問に対して最も高いベースライン精度を達成する。
- プレアンブルとERは、CCAのテキスト質問でGPT-4の性能を向上させる(例:あるシナリオで79%から84%へ)。
- RAGは、複数選択式CCA質問においてGPT-3.5とGPT-4の性能を大幅に向上させ、GPT-4は特定の設定で最大97%に達する。
- ERはGPT-4とGPT-3.5のテキスト質問で改善をもたらすが、向上はモデルとシナリオにより異なる。
- サンプルの複数選択式質問全体で、RAGとERを組み合わせると最も強い性能を示す(GPT-4:あるシナリオで97%)。
- GPT-4の性能はときに人間の性能に近づく、あるデータセットでは超えることもあり、試験および農学認証の文脈での可能性を示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。