[論文レビュー] GPT-Driver: Learning to Drive with GPT
GPT-Driver は planning を言語モデリングとして扱うことで GPT-3.5 をモーションプランナーとして再利用し、 nuScenes における自動運転で正確な軌道と解釈可能な推論過程を生み出す、プロンプト生成・推論・ファインチューニング戦略を用いる。
We present a simple yet effective approach that can transform the OpenAI GPT-3.5 model into a reliable motion planner for autonomous vehicles. Motion planning is a core challenge in autonomous driving, aiming to plan a driving trajectory that is safe and comfortable. Existing motion planners predominantly leverage heuristic methods to forecast driving trajectories, yet these approaches demonstrate insufficient generalization capabilities in the face of novel and unseen driving scenarios. In this paper, we propose a novel approach to motion planning that capitalizes on the strong reasoning capabilities and generalization potential inherent to Large Language Models (LLMs). The fundamental insight of our approach is the reformulation of motion planning as a language modeling problem, a perspective not previously explored. Specifically, we represent the planner inputs and outputs as language tokens, and leverage the LLM to generate driving trajectories through a language description of coordinate positions. Furthermore, we propose a novel prompting-reasoning-finetuning strategy to stimulate the numerical reasoning potential of the LLM. With this strategy, the LLM can describe highly precise trajectory coordinates and also its internal decision-making process in natural language. We evaluate our approach on the large-scale nuScenes dataset, and extensive experiments substantiate the effectiveness, generalization ability, and interpretability of our GPT-based motion planner. Code is now available at https://github.com/PointsCoder/GPT-Driver.
研究の動機と目的
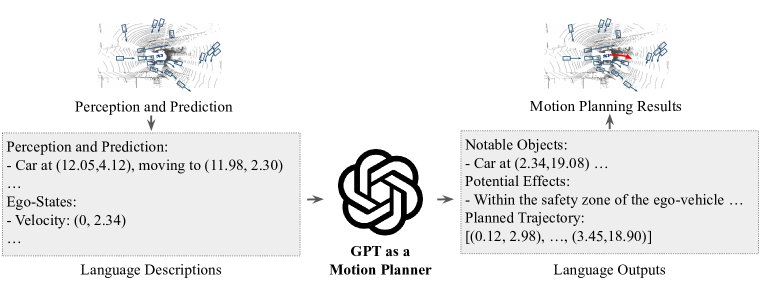
- 入力と出力を言語トークンとしてエンコードすることで、モーションプランニングを言語モデリング問題に変換する。
- 数値的精度と意思決定の透明性を向上させるために、 prompting-reasoning-finetuning 戦略を用いて GPT-3.5 を活用する。
- nuScenes データセットでこのアプローチを実証し、最先端のモーションプランナーと比較する。
- GPT ベースのプランナーの汎化能力、ファーストショット学習能力、解釈可能性を評価する。
提案手法
- 観測と自車状態を GPT-3.5 のトークナイザベースのエンコーディングによる言語プロンプトとして表現する。
- 軌道生成を、ウェイポイント座標に対応するトークンの系列を予測することとして定式化する。
- 思考の連鎖を引き出すための prompting-reasoning-finetuning パイプラインを用いて、言語で軌道を生成する。
- 人間の運転軌跡でLLMの出力をファインチューニングして現実世界の挙動と合わせる。
- 計画された軌道とモデルの推論過程の両方を提供して解釈性を高める。
実験結果
リサーチクエスチョン
- RQ1大規模言語モデル(LLM)を自動運転における高精度・低レベルのモーションプランニングに利用できるか?
- RQ2計画を言語モデリング問題へ変換することは、従来のプランナーより汎化性と解釈性を向上させるか?
- RQ3prompting、推論、ファインチューニング戦略が軌道の正確さと安全性に与える影響はどの程度か?
主な発見
| Method | L2 (1s) | L2 (2s) | L2 (3s) | L2 Avg | Collision (1s) | Collision (2s) | Collision (3s) | Collision Avg |
|---|---|---|---|---|---|---|---|---|
| ST-P3 Hu et al. (2022) | 1.33 | 2.11 | 2.90 | 2.11 | 0.23 | 0.62 | 1.27 | 0.71 |
| VAD Jiang et al. (2023) | 0.17 | 0.34 | 0.60 | 0.37 | 0.07 | 0.10 | 0.24 | 0.14 |
| GPT-Driver (ours) | 0.20 | 0.40 | 0.70 | 0.44 | 0.04 | 0.12 | 0.36 | 0.17 |
| UniAD Hu et al. (2023) | 5.37 | 1.80 | 1.42 | 1.03 | 6.86 | 1.31 | 0.49 | 0.31 |
| GPT-Driver (in-context learning) | 2.41 | 3.11 | 4.00 | 3.17 | 4.20 | 5.13 | 6.58 | 5.30 |
| GPT-Driver (fine-tuning) | 0.27 | 0.74 | 1.52 | 0.84 | 0.07 | 0.15 | 1.10 | 0.44 |
- GPT-Driver は nuScenes で 1s, 2s, 3s のホライゾンで従来手法に対する L2 誤差を大幅に改善した。
- このアプローチは競争力のある衝突率を達成し、最先端のプランナーと同等の安全性を示している。
- ファインチューニングはこのタスクでイン-context 学習を上回り、データ効率と汎化性の強さを示している。
- GPT-Driver は少数ショットの汎化を示し、UniAD に比べて限られた学習データで良好に機能する。
- 軌道とともに思考の連鎖のような推論を含めることで、モデルは解釈可能な出力を提供する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。