[論文レビュー] GPT-NER: Named Entity Recognition via Large Language Models
GPT-NERはNERをLLMのテキスト生成タスクとして再定義し、自己検証を伴うエンティティタグ付き出力を用いて幻覚を減らし、特に低リソース環境で教師付きベースラインと競合する成果を達成する。
Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
研究の動機と目的
- NERとLLM生成のギャップを埋めるため、NERを生成タスクとして再定義する。
- LLMsに対して適切に構成されたデモンストレーションを提供するプロンプト設計と取得戦略を設計する。
- 自己検証ステップによってNERにおけるLLMの幻覚を軽減する。
- 平坦およびネストされたNERベンチマークでGPT-NERを評価し、低リソース性能を分析する。
提案手法
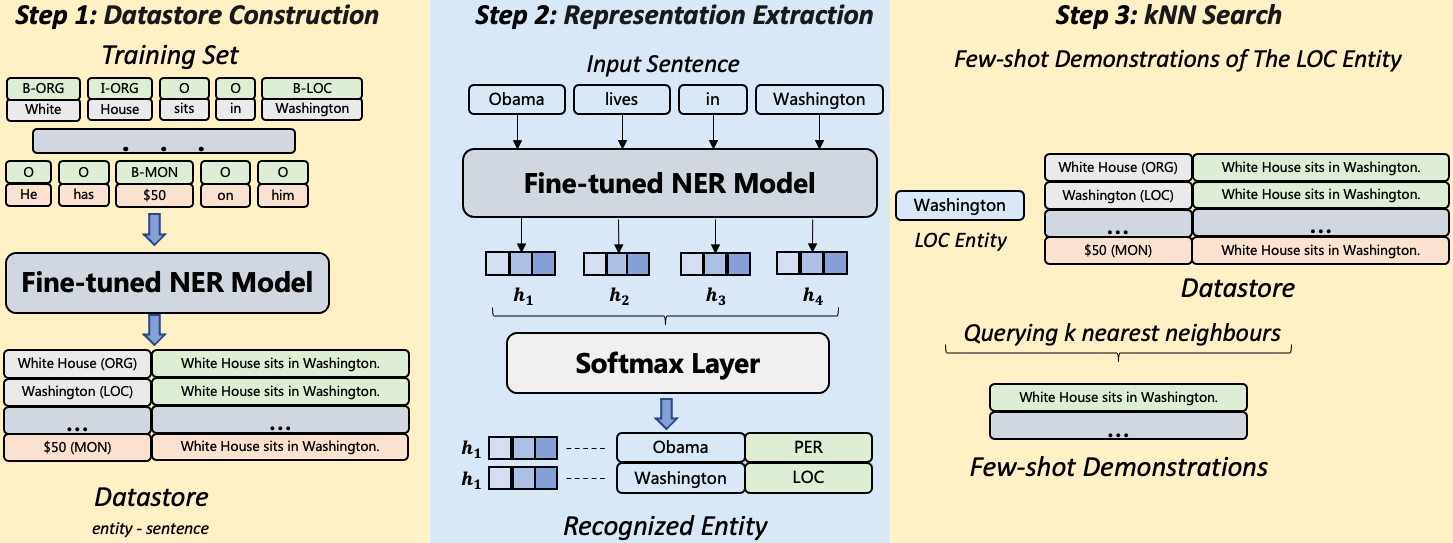
- NERを特殊トークン @@ および ## でエンティティを囲むことによりテキスト生成タスクへ変換し、ラベル付き系列を生成する。
- タスク説明、少数ショットデモ、入力文セクションを含むプロンプト構築でLLMsを誘導する。
- トークンレベルでk-nearest neighborsを用いてデモを取得し、関連する例を提供する。
- 出力を確定する前に抽出されたエンティティが対象ラベルに属するかをモデルが検証する自己検証ステップを導入する。
- GPT-3(davinci-003)をバックボーンとして固定生成設定で使用し、標準NERデータセットで評価する。

実験結果
リサーチクエスチョン
- RQ1マーク付き出力を用いたGPT風生成は、平坦およびネストされたデータセットで教師付きNERベースラインと競合できるか?
- RQ2トークンレベルのkNNデモ取得は、ランダムまたは文レベル取得よりNER性能を向上させるか?
- RQ3自己検証ステップは幻覚を削減しNER出力の精度を向上させるか?
- RQ4低リソースおよび少数ショットの状況でGPT-NERは教師ありモデルと比較してどうであるか?
- RQ5デモンストレーション取得にエンティティレベルの埋め込みを使用することがNERタスクに与える影響は?
主な発見
- GPT-NERは平坦NERデータセットで教師付きベースラインと同等のパフォーマンスを達成し、いくつかの設定でSOTAに近づく。
- エンティティレベル(トークン認識)kNN取得は、デモのためのランダムおよび文レベルの取得を著しく上回る。
- 自己検証は過信的なNULLラベリングを抑制することで追加の向上をもたらし、F1スコアを改善する。
- GPT-NERは低リソースおよび少数ショット設定で強い利点を示し、ラベル付きデータが乏しい場合には教師ありモデルを上回る。
- より大きなトークン予算でも性能向上が持続し、高容量のLLM(例: GPT-4)でのさらなる改善余地を示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。