[論文レビュー] GPTAraEval: A Comprehensive Evaluation of ChatGPT on Arabic NLP
本論文は、ChatGPT(GPT-3.5-turbo)を対象に、44のアラビア語NLPタスクを60以上のデータセットにわたって大規模に自動評価および人間評価を実施し、ChatGPTが小規模なファインチューニング済みアラビア語モデルと比較して一般に性能を下回ることを示し、特に方言アラビア語で顕著で、GPT-4は一般的にChatGPTを上回る。
ChatGPT's emergence heralds a transformative phase in NLP, particularly demonstrated through its excellent performance on many English benchmarks. However, the model's efficacy across diverse linguistic contexts remains largely uncharted territory. This work aims to bridge this knowledge gap, with a primary focus on assessing ChatGPT's capabilities on Arabic languages and dialectal varieties. Our comprehensive study conducts a large-scale automated and human evaluation of ChatGPT, encompassing 44 distinct language understanding and generation tasks on over 60 different datasets. To our knowledge, this marks the first extensive performance analysis of ChatGPT's deployment in Arabic NLP. Our findings indicate that, despite its remarkable performance in English, ChatGPT is consistently surpassed by smaller models that have undergone finetuning on Arabic. We further undertake a meticulous comparison of ChatGPT and GPT-4's Modern Standard Arabic (MSA) and Dialectal Arabic (DA), unveiling the relative shortcomings of both models in handling Arabic dialects compared to MSA. Although we further explore and confirm the utility of employing GPT-4 as a potential alternative for human evaluation, our work adds to a growing body of research underscoring the limitations of ChatGPT.
研究の動機と目的
- 広範なアラビア語のNLUおよびNLGタスクとデータセットにおけるChatGPTの性能を評価する。
- ChatGPTをBLOOMZとファインチューニング済みのアラビア語ベースライン(MARBERT V2、AraT5)と比較する。
- 現代標準アラビア語(MSA)と方言アラビア語(DA)の性能差を分析する。
- アラビア語生成タスクにおける人間評価とGPT-4ベースの評価の信頼性を評価する。
提案手法
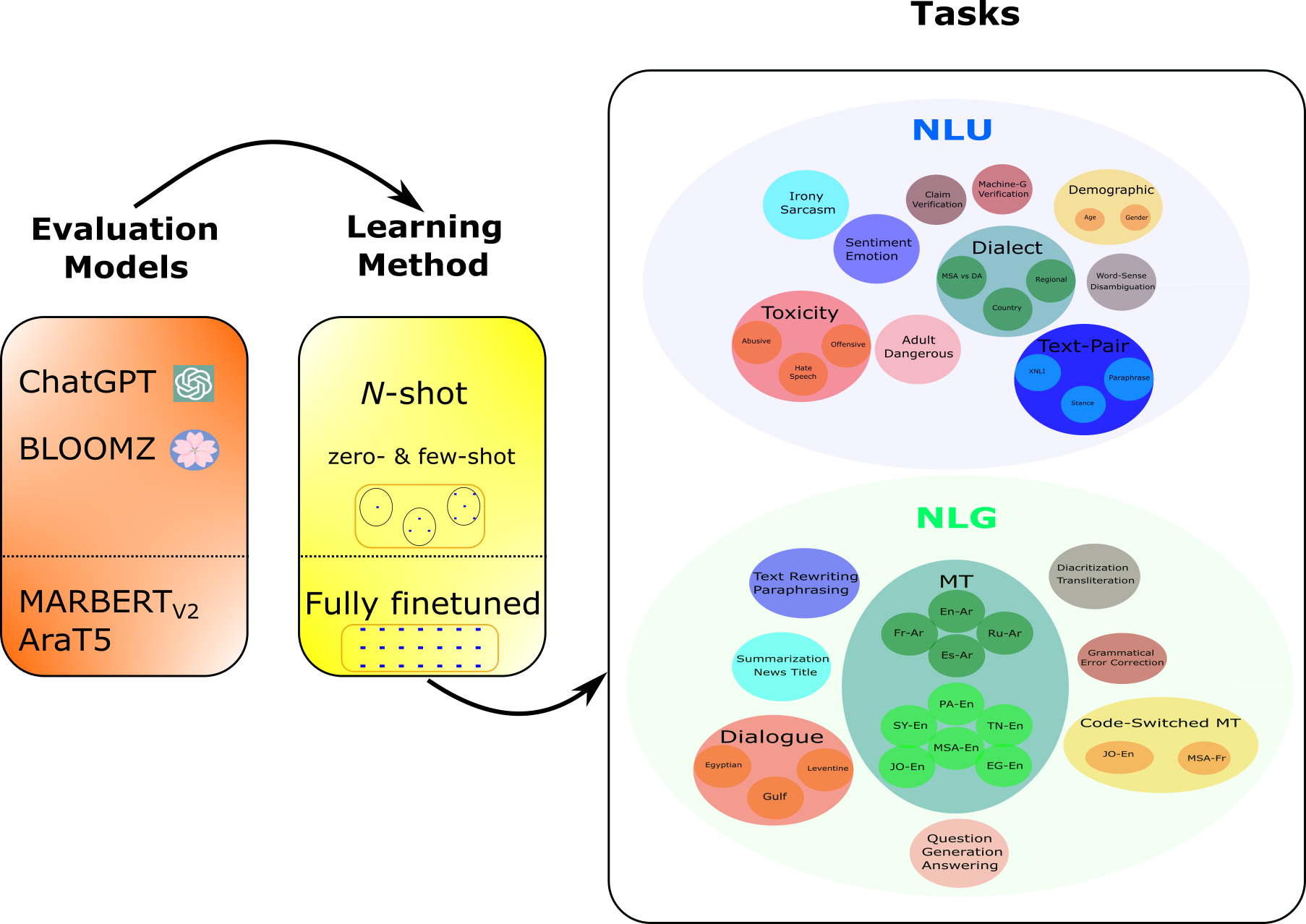
- NLUとNLGのために、44のアラビア語NLPタスクを60以上のデータセットにまたがって使用する。
- ChatGPT(gpt-3.5-turbo-0301)を0-, 3-, 5-, 10-shotプロンプトと英語のユニバーサルプロンプトテンプレートで評価する。
- BLOOMZ-7.1B(アラビア語を含むファインチューニング済み)とファインチューニング済みMARBERT V2およびAraT5のベースラインと比較する。
- NLUにはmacro-F1を、NLGにはタスク適切な指標を適用する。
- 社内のMSA対DA分類器とORCA連携タスクを用いた方言特化評価を実施し、DA対MSAでのChatGPTとGPT-4を比較する。
- 自動指標に加えて、8つのNLGタスクで人間評価を実施し、評価基準としてGPT-4をベンチマークとして使用する。
実験結果
リサーチクエスチョン
- RQ1ChatGPTは、アラビア語特化のファインチューニング済みモデルと比較して、広範なアラビア語NLPベンチマークでどの程度の性能を示すか?
- RQ2ChatGPTは現代標準アラビア語と比較して方言アラビア語で苦戦しているか?
- RQ3GPT-4は、方言を含むアラビア語のNLU/NLGタスクで一貫してChatGPTより強いか?
- RQ4GPT-4はアラビア語生成タスクにおいて人間の判断と一致する信頼できる自動評価を提供できるか?
主な発見
- ChatGPTは、ほとんどのタスクで小規模なファインチューニング済みアラビア語モデルと比べて一般的に性能が劣る。
- MARBERT V2はNLUタスクでChatGPTより著しく高いmacro-F1スコアを出すことが多い。
- 方言アラビア語では、ChatGPTの性能はMSAを下回り、一般的にGPT-4に敗れ、GPT-4は複数のDAタスクでより安定した結果を示す。
- NLGタスクでは、AraT5は通常、ChatGPTとBLOOMZの双方を上回る。一方、ChatGPTは多くのタスクでBLOOMZを上回るが、AraT5には及ばない。
- 言い換えや一部のテキストペアタスクでは、より多くのショットでChatGPTの向上が顕著で、時には完全にファインチューニングされたMARBERT V2を超えることもあるが、すべてのタスクで一貫しているわけではない。
- GPT-4によるモデル出力の評価は人間評価とかなり一致しており、アラビア語生成タスクにおける人間評価の有効な代理指標となり得ることを示唆している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。