[論文レビュー] GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
本論文は新しい曝露評価規準をO*NETのタスクデータに適用し、人間とGPT-4の分類を用いて、LLMsが米国の作業タスクと職業にどのような影響を与え得るかを推定します。広範な曝露と、LLM搭載ソフトウェアを使用した場合の顕著な効果を示しています。
We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.
研究の動機と目的
- LLMs(GPTs)がモデルの能力だけでは説明できない形で労働市場に与える影響を理解する動機付け。
- 人間とGPT-4の分類を用いてタスク曝露を測定する規準を開発・適用する。
- タスクレベルの曝露を職業・業種レベルの洞察へ集約する。
- 経済的影響を拡大する補完技術とLLM搭載ソフトウェアの役割を強調する。
提案手法
- O*NET DWAsおよびタスク(19,265タスク; 2,087 DWAs)を用いてタスク-および職業レベルの曝露測定を構築する。
- 人間の判断とGPT-4分類で曝露を50%の時間短縮ルーブリックの下で注釈する。
- 3つの曝露指標を定義する:alpha(E1)、beta(E1 + 0.5*E2)、および zeta(E1 + E2)。
- 補足タスクに対して二重に重みづけしたコアタスクを用いて職業へタスク曝露を集約する。
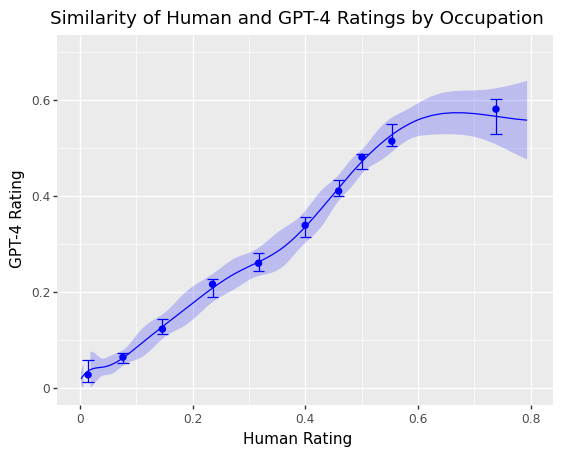
- 人間とGPT-4の注釈を比較し、職業レベルでの同意と相関を評価する。
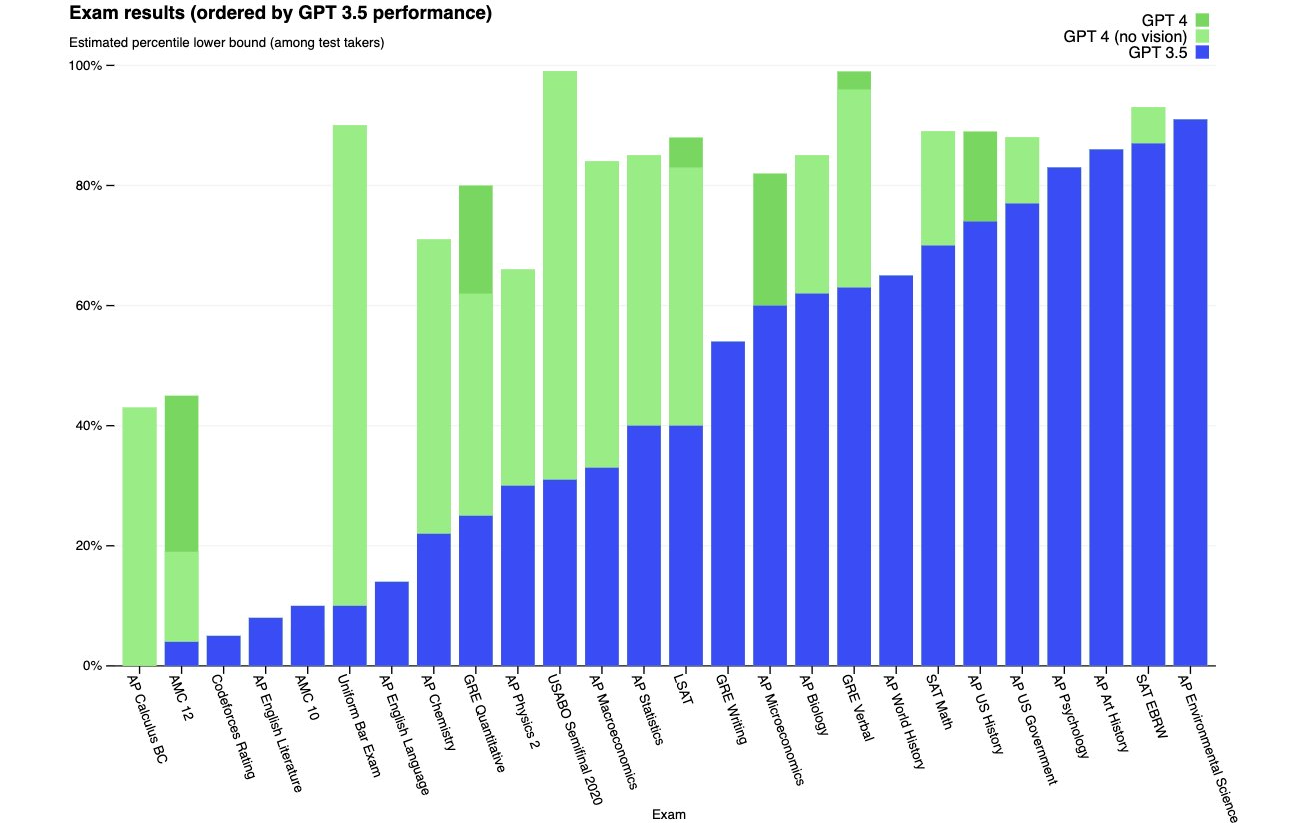
実験結果
リサーチクエスチョン
- RQ1LLMsの曝露がタスクレベルで米国の職業のどの程度に及ぶか?
- RQ2人間の評価とGPT-4の分類で曝露推定はどう異なるか?
- RQ3LLMsだけとLLM搭載ソフトウェアのタスク完了時間への影響はどうなるか?
- RQ4職業・賃金レベル・業界別に曝露パターンはどのように変化するか?
主な発見
- 労働者のおおよそ80%が、曝露されたタスクが少なくとも10%ある職業(beta指標)に属している。
- 約19%の労働者が、曝露されたタスクが少なくとも50%ある職業(beta指標)にいる。
- 平均して、LLM単独では全労働者のタスクの約15%が大幅に速く完了できる可能性がある;LLM搭載ソフトウェアを用いるとこれが47–56%へ増加する。
- 職業レベルの平均alpha値は約0.14–0.15程度;betaは人間で約0.30、GPT-4で約0.34;zetaはより高く、職業全体で実質的な曝露の可能性を示す。
- 曝露は高賃金の職務や情報処理産業で高い傾向があり、曝露はプログラミングと執筆能力と相関し、科学/批判的思考能力と負の相関を示す。
- 人間とGPT-4の注釈は職業レベルのLLMシステム曝露に関して substantial agreement がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。