[論文レビュー] GRAG: Graph Retrieval-Augmented Generation
GRAG はクエリ関連のテキストサブグラフをソフトプリuningとデュアルプロンプト(ハードなテキストプロンプトとソフトなグラフプロンプト)で取得し、LLMs をグラフベースの多段推論に補強する。従来のRAG法を上回り、幻覚を減らす。
Naive Retrieval-Augmented Generation (RAG) focuses on individual documents during retrieval and, as a result, falls short in handling networked documents which are very popular in many applications such as citation graphs, social media, and knowledge graphs. To overcome this limitation, we introduce Graph Retrieval-Augmented Generation (GRAG), which tackles the fundamental challenges in retrieving textual subgraphs and integrating the joint textual and topological information into Large Language Models (LLMs) to enhance its generation. To enable efficient textual subgraph retrieval, we propose a novel divide-and-conquer strategy that retrieves the optimal subgraph structure in linear time. To achieve graph context-aware generation, incorporate textual graphs into LLMs through two complementary views-the text view and the graph view-enabling LLMs to more effectively comprehend and utilize the graph context. Extensive experiments on graph reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods. Our datasets as well as codes of GRAG are available at https://github.com/HuieL/GRAG.
研究の動機と目的
- トポロジーがテキストだけではなく重要となるテキストグラフ上で、堅牢な推論を促進する。
- NP困難なサブグラフ探索に対処するための効率的なサブグラフ取得機構を提案する。
- 取得と生成の過程で、テキスト内容とグラフトポロジーの両方を保持する。
- LLMs向けに、テキストサブグラフを階層的な記述へロスレスに変換するプロンプト戦略を導入する。
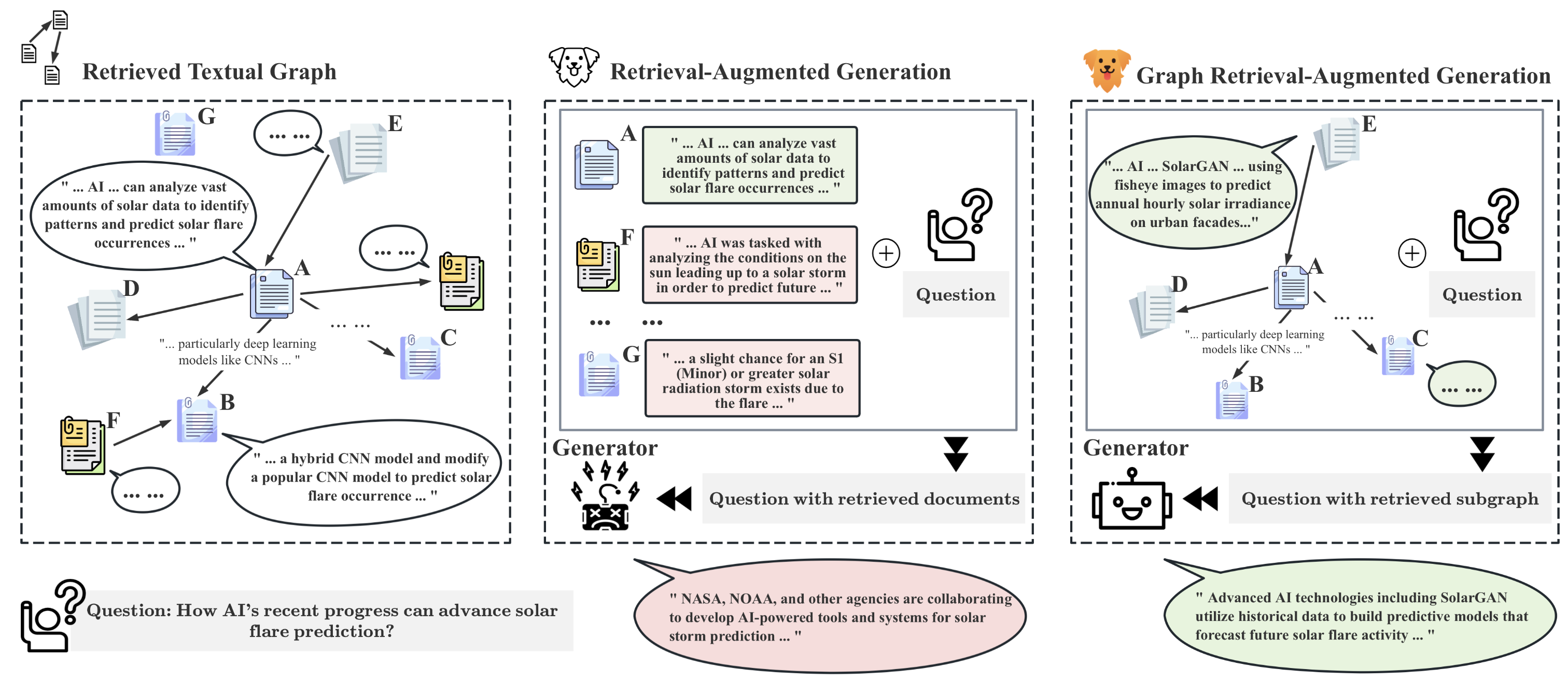
提案手法
- k-ホップエゴグラフを索引付けし、事前学習済み言語モデルを用いてグラフ埋め込みとしてエンコードする。
- 質問埋め込みとサブグラフ埋め込みとのコサイン類似度に基づき、上位N件のテキストサブグラフを取得する。
- 質問とサブグラフの距離から学習される関連度スカラーを介して、ノード/エッジの寄与度をスケーリングするソフトプリuningを適用する。
- ハードプロンプト(サブグラフの階層的テキスト記述)とソフトプロンプト(グラフ埋め込み)を組み合わせて回答を生成し、GNNとMLPを介してグラフ埋め込みをLLMのテキストベクトルに整合させる。
実験結果
リサーチクエスチョン
- RQ1大規模なテキストグラフにおいて、 exhaustive search なしでクエリ関連のサブグラフを効率的に取得するにはどうすればよいか。
- RQ2生成の過程で、テキスト情報とトポロジー情報の両方をどのように保持・統合するか。
- RQ3 retrieved サブグラフを付与した凍結LLM は、グラフ推論タスクでファインチューニング済みLLMと比較して優れているか。
- RQ4ソフトプロンプティングは、巨大なトレーニングコストをかけずにグラフ対応生成を効果的に導くか。
主な発見
| Model | Φ(g) | Fine-tuning | WebQSP F1 | WebQSP Hit@1 | WebQSP Recall | WebQSP Acc | ExplaGraphs F1 | ExplaGraphs Hit@1 | ExplaGraphs Recall | ExplaGraphs Acc |
|---|---|---|---|---|---|---|---|---|---|---|
| LLM only | ✗ | ✗ | 0.2555 | 0.4148 | 0.2920 | 0.3394 | ||||
| LLM_LoRA | ✗ | ✓ | 0.4295 | 0.6186 | 0.4193 | 0.8927 | ||||
| BM25 | ✗ | ✗ | 0.2999 | 0.4287 | 0.2879 | 0.6011 | ||||
| MiniLM-L12-v2 | ✗ | ✗ | 0.3485 | 0.4730 | 0.3289 | 0.6011 | ||||
| LaBSE | ✗ | ✗ | 0.3280 | 0.4496 | 0.3126 | 0.6011 | ||||
| mContriever-Base | ✗ | ✗ | 0.3172 | 0.4453 | 0.3047 | 0.5866 | ||||
| E5-Base | ✗ | ✗ | 0.3421 | 0.4705 | 0.3254 | 0.6011 | ||||
| G-Retriever | ✓ | ✗ | 0.4674 | 0.6808 | 0.4579 | 0.8825 | ||||
| G-Retriever_LoRA | ✓ | ✓ | 0.5023 | 0.7016 | 0.5002 | 0.9042 | ||||
| GRAG | ✓ | ✗ | 0.5022 | 0.7236 | 0.5099 | 0.9223 | 0.NOP | 0.NOP | 0.NOP | 0.NOP |
| GRAG_LoRA | ✓ | ✓ | 0.5041 | 0.7275 | 0.5112 | 0.9274 | 0.NOP | 0.NOP | 0.NOP | 0.NOP |
- GRAG はグラフ多段推論ベンチマーク(WebQSP と ExplaGraphs)において、最新のRAGベースラインおよびLLMのみのアプローチを上回る。
- GRAG を組み込んだ凍結LLM は、全タスクでファインチューニング済みLLMs を上回り、トレーニングコストが低い。
- ソフトプリuningとサブグラフレベルの取得は幻覚を減らし、事実 grounding を向上させることを、人間評価の有効事象引用数で示している。
- retrieved subgraphs をソフトグラフトークンとして用いることは、テキストのみまたは網羅的サブグラフ探索のみを用いるよりも良い性能を発揮する。
- クロスデータセット転移では、あるデータセットで訓練した GRAG が他のデータセットの性能を改善できる(例:WebQSP から ExplaGraphs へ)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。