[論文レビュー] Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
本論文はプレ登録的に Lexis+ AI、Westlaw AI-Assisted Research、Ask Practical Law AI を GPT-4 と比較評価し、各ツールで顕著な幻覚と精度のばらつきを示す。
Legal practice has witnessed a sharp rise in products incorporating artificial intelligence (AI). Such tools are designed to assist with a wide range of core legal tasks, from search and summarization of caselaw to document drafting. But the large language models used in these tools are prone to "hallucinate," or make up false information, making their use risky in high-stakes domains. Recently, certain legal research providers have touted methods such as retrieval-augmented generation (RAG) as "eliminating" (Casetext, 2023) or "avoid[ing]" hallucinations (Thomson Reuters, 2023), or guaranteeing "hallucination-free" legal citations (LexisNexis, 2023). Because of the closed nature of these systems, systematically assessing these claims is challenging. In this article, we design and report on the first preregistered empirical evaluation of AI-driven legal research tools. We demonstrate that the providers' claims are overstated. While hallucinations are reduced relative to general-purpose chatbots (GPT-4), we find that the AI research tools made by LexisNexis (Lexis+ AI) and Thomson Reuters (Westlaw AI-Assisted Research and Ask Practical Law AI) each hallucinate between 17% and 33% of the time. We also document substantial differences between systems in responsiveness and accuracy. Our article makes four key contributions. It is the first to assess and report the performance of RAG-based proprietary legal AI tools. Second, it introduces a comprehensive, preregistered dataset for identifying and understanding vulnerabilities in these systems. Third, it proposes a clear typology for differentiating between hallucinations and accurate legal responses. Last, it provides evidence to inform the responsibilities of legal professionals in supervising and verifying AI outputs, which remains a central open question for the responsible integration of AI into law.
研究の動機と目的
- 主要なAI法務リサーチツールにおける幻覚の有病率と性質を評価する。
- 系統的評価のための、事前登録されたドメイン特化の法的クエリデータセットを作成する。
- RAGベースのシステムにおける幻覚と正確な法的回答を区別する類型を開発する。
- 法的タスクでAIを使用する弁護士の監督と検証実践を導く証拠を提供する。
提案手法
- 法的出力の正確さと根拠性を区別する正式な枠組みを定義する。
- 200件超の法的クエリの事前登録データセットを手動で作成する。
- データセット上で Lexis+ AI、Westlaw AI-Assisted Research、Ask Practical Law AI、および GPT-4 を評価する。
- 出力を正確さと権威への忠実度の点で手動でレビューする。
- RAGベースのツールを汎用モデル(GPT-4)と比較し、相対的な改善と残るリスクを評価する。
実験結果
リサーチクエスチョン
- RQ1実世界のクエリにおける主要AI法務リサーチツールの幻覚率はどれくらいか。
- RQ2これらのツールは権威あるソースに対して、正確さと根拠性の点でどう比較されるか。
- RQ3RAGベースのアプローチは、一般目的のLLMsと比較して幻覚を意味のある程度低減するか。
- RQ4弁護士の監督とAI出力の検証に関する実務的な影響は何か。
主な発見
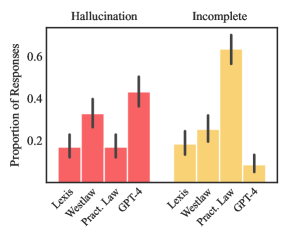
- Lexis+ AI は 65% のクエリに対して正確に回答する。
- Westlaw AI-Assisted Research は 42% の頻度で正確。
- Ask Practical Law AI は 60%を超えるクエリで不完全または根拠なしの回答を提供する。
- すべてのツールは、特定のツールで 17%〜33% の無視できない幻覚率を示す。
- RAGはGPT-4に対する性能を向上させるが、法的タスクにおける幻覚を完全には排除しない。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。