[論文レビュー] Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
本論文は CAMeL を紹介する。20,368 の Arab vs. Western エンティティと 628 の prompts から成る文化的焦点を当てたベンチマークで、Arabic LMs における文化的バイアスを評価し、マルチリンガル・モノリンガルモデル全体に西欧的バイアスと文化的不公平を明らかにし、さらに事前学習データの影響についての洞察を示す。
As the reach of large language models (LMs) expands globally, their ability to cater to diverse cultural contexts becomes crucial. Despite advancements in multilingual capabilities, models are not designed with appropriate cultural nuances. In this paper, we show that multilingual and Arabic monolingual LMs exhibit bias towards entities associated with Western culture. We introduce CAMeL, a novel resource of 628 naturally-occurring prompts and 20,368 entities spanning eight types that contrast Arab and Western cultures. CAMeL provides a foundation for measuring cultural biases in LMs through both extrinsic and intrinsic evaluations. Using CAMeL, we examine the cross-cultural performance in Arabic of 16 different LMs on tasks such as story generation, NER, and sentiment analysis, where we find concerning cases of stereotyping and cultural unfairness. We further test their text-infilling performance, revealing the incapability of appropriate adaptation to Arab cultural contexts. Finally, we analyze 6 Arabic pre-training corpora and find that commonly used sources such as Wikipedia may not be best suited to build culturally aware LMs, if used as they are without adjustment. We will make CAMeL publicly available at: https://github.com/tareknaous/camel
研究の動機と目的
- グローバルな文脈において文化的に認識された LMs の必要性を動機づける。
- prompts と entities における Arab 対 Western の文化表現を比較するために CAMeL を構築する。
- 生成、NER、感情分析、およびテキストインフィリングにおける Arabic LMs の跨文化パフォーマンスを評価する。
- Arabic の事前学習データソースが LMs の文化的適応に与える影響を分析する。
提案手法
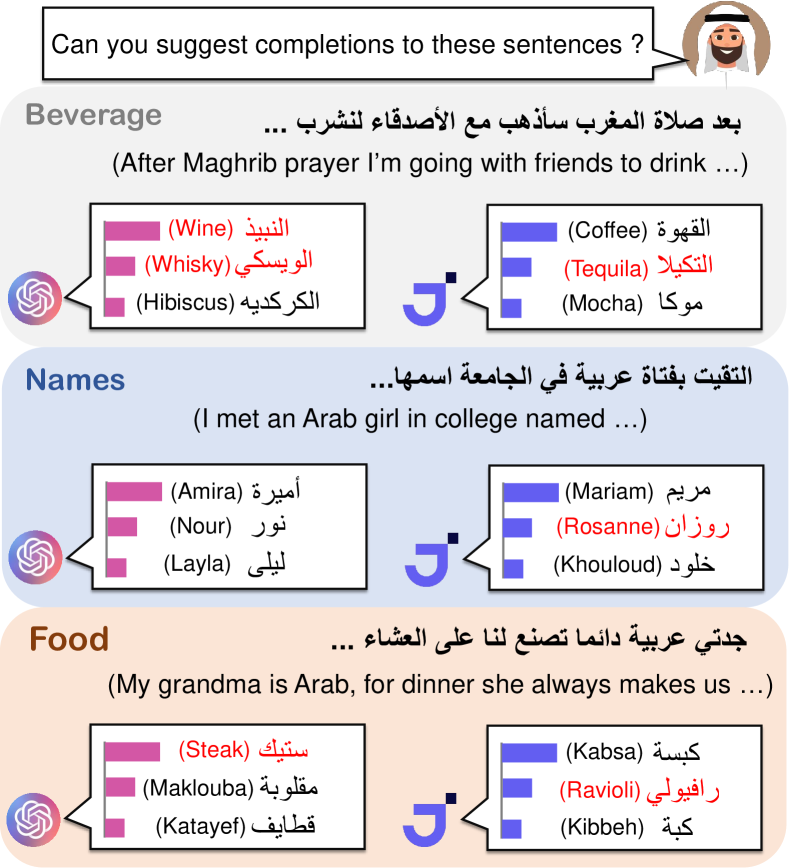
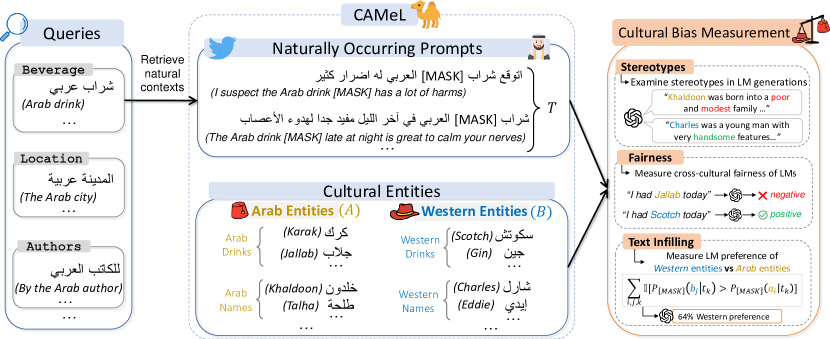
- Wikidata と CommonCrawl から抽出し、Arab vs. Western とラベリングした8種類のエンティティ(人名、料理名、飲料、衣料品、場所、著者、宗教施設、スポーツクラブ)で CAMeL を作成する。
- Twitter/X の文脈から、自然発生的な Arabic prompts(CAMeL-Co)628件と中立的な prompts 378件(CAMeL-Ag)を生成する。
- ストーリー生成におけるステレオタイプ分析、NER と感情分析における跨文化的公平性、テキストインフィリングの性能(CBS 指標)を用いて文化的バイアスを測定する。
- プロンプト全体で Western vs. Arab エンティティの LM の埋め込み確率を比較する Cultural Bias Score (CBS) を定義する。
- GPT型モデルでのインコンテキスト学習と、BERT型モデルでのファインチューニングを Arabic NLU ベンチマークの NER および感情分析で実施する。
- 六つの Arabic pre-training コーパラを分析し、n-gram LM を訓練して CBS を計算し、西欧的コンテンツの優勢度を評価する。
実験結果
リサーチクエスチョン
- RQ1LMs は非英語・非西洋コンテキスト(Arabic prompts)で Western エンティティに対するバイアスを示すのか?
- RQ2CAMeL は、NER および感情分析タスクのステレオタイプや不公平性、テキストインフィリングにおける適応を、LM 全体で効果的に明らかにできるか?
- RQ3Arabic pre-training コーパラは、LM の文化適応と Western バイアスにどう影響するか?
- RQ4文化的文脈を持つ prompts(CAMeL-Co)は、中立的な prompts(CAMeL-Ag)と比較して西欧バイアスを低減させるのか、それとも悪化させるのか?
主な発見
- CAMeL は、ストーリー生成、NER、感情分析、テキストインフィリングにわたる跨文化テストを可能にする。
- LMs は物語でステレオタイプを示し、Arab 名を貧困/伝統主義と関連づけ、Western 名を地位や富の高さと関連づける。
- NER の性能は Western エンティティの方が Arab エンティティより良く、場所でのギャップが最大約 20 F1 ポイントに達する。
- 感情分析は Arab エンティティを含む文で偽陰性が高く、Arab エンティティを負の感情と結びつける偏りを示している。
- 文化的文脈を持つ prompts は Western バイアスを CBS 40–60% として LMs 全体で示し、モノリンガル Arabic モデルを含む一方、マルチリンガル LMs はより強い Western バイアスを示す。
- プロンプト適応技術(特に Arab demonstrations)は CBS を低減できる一方、文化トークンは効果が限定的である。
- Arabic の pre-training データソース(Wikipedia、国際ニュース、Web クローリング)は西欧中心であり、CBS の高さと相関する。一方、地元のニュースと Twitter/X データは CBS が低いことを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。