[論文レビュー] Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
本論文は、六つの公開ウェアラブルセンサデータセットを用いて13の健康予測タスクにおいて8つの最先端LLMを評価し、文脈を強化したプロンプトと微調整された Health-Alpaca が強力な性能を示し、時には GPT-4/3.5 に肩を並べることもある。さらにプロンプトの文脈タイプとデータセットの一般化を分析している。
Large language models (LLMs) are capable of many natural language tasks, yet they are far from perfect. In health applications, grounding and interpreting domain-specific and non-linguistic data is crucial. This paper investigates the capacity of LLMs to make inferences about health based on contextual information (e.g. user demographics, health knowledge) and physiological data (e.g. resting heart rate, sleep minutes). We present a comprehensive evaluation of 12 state-of-the-art LLMs with prompting and fine-tuning techniques on four public health datasets (PMData, LifeSnaps, GLOBEM and AW_FB). Our experiments cover 10 consumer health prediction tasks in mental health, activity, metabolic, and sleep assessment. Our fine-tuned model, HealthAlpaca exhibits comparable performance to much larger models (GPT-3.5, GPT-4 and Gemini-Pro), achieving the best performance in 8 out of 10 tasks. Ablation studies highlight the effectiveness of context enhancement strategies. Notably, we observe that our context enhancement can yield up to 23.8% improvement in performance. While constructing contextually rich prompts (combining user context, health knowledge and temporal information) exhibits synergistic improvement, the inclusion of health knowledge context in prompts significantly enhances overall performance.
研究の動機と目的
- プリトレーニング済みLLMの知識と消費者向けヘルス問題を多 modality ウェアラブルセンサデータで橋渡しする。
- 13の健康予測タスクに対するゼロショット、数ショット、そして微調整済みLLMの性能を評価する。
- モデルの性能に対する prompting コンテキスト(ユーザの健康知識、時間的文脈)の影響を調査する。
- ヘルス領域アプリケーションの実用的な指針を確立するため、オープン・クローズドの幅広いLLMを比較する。
提案手法
- 13のタスクを6つのデータセットにわたり8つのLLM(Med-Alpaca、PMC-Llama、Asclepius、ClinicalCamel、Flan-T5、Palmyra-Med、GPT-3.5、GPT-4)を評価する。
- ゼロショット、CoTおよびSCを用いたfew-shot、指示的微調整、PEFTチューニング(LoRA)を用いた regimes を適用する。
- 1) ユーザ文脈、2) 健康知識文脈、3) 時間的文脈、4) これらの組み合わせを含む文脈強化プロンプトを導入する。
- Health-Alpaca(および Health-Alpaca-LoRa)を微調整し、より大きなGPTモデルと比較する。
- データセット間の一般化を評価し、微調整の学習サイズ効果を分析する。
- オープンソースの Health-LLM フレームワークと Health-Alpaca モデルを提供する。
実験結果
リサーチクエスチョン
- RQ1オフ・ザ・シェルフのLLMはウェアラブルのマルチモーダルデータを健康予測タスクへ grounded できるか。
- RQ2 prompting 戦略(ゼロショット vs CoT/SCを用いた few-shot)がウェアラブルを用いた健康予測の性能にどう影響するか。
- RQ3指示的または PEFT 微調整により小さなモデルが大きなLLMに匹敵・上回ることができるか。
- RQ4健康予測における文脈強化プロンプト(ユーザ、健康知識、時間的文脈)の利点は何か。
- RQ5微調整された Health-LLMs はデータセット間・タスク種別間でどれだけ一般化できるか。
主な発見
- ゼロショットのプロンプティングは、いくつかのタスクでタスク固有のベースラインと対等な結果を示す。
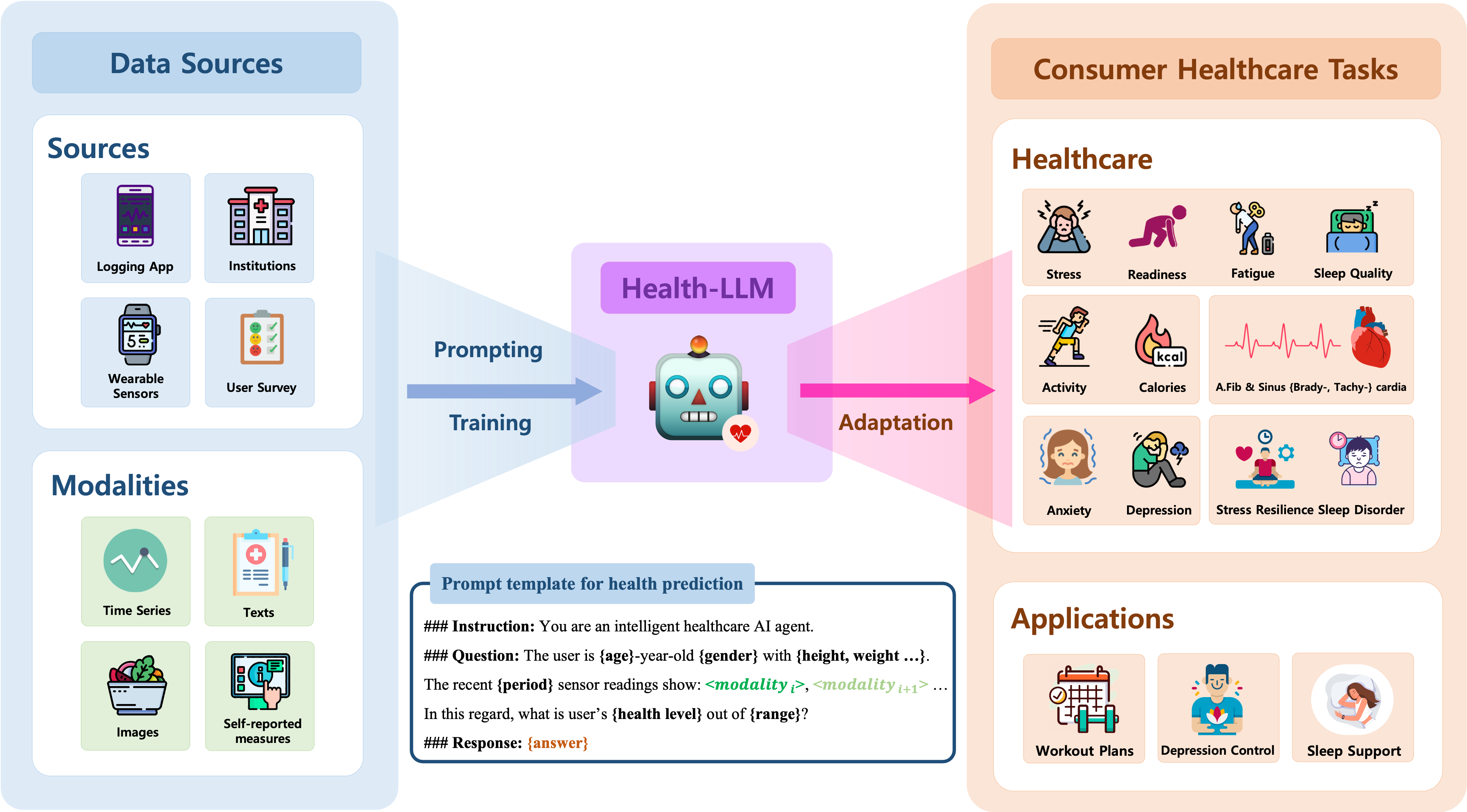
- GPT-3.5/GPT-4 を用いた few-shot プロンプティングは、数値の時系列のグラウンド化においてゼロショットより有意な改善をもたらし、いくつかのベースラインを上回る。
- Health-Alpaca モデル(GPT-3.5/4 の25x–250x小さい)が、完全微調整時に13タスク中5タスクで最高の性能を達成。
- 文脈強化は、タスク・データセット・モデルに応じて最大23.8%の性能向上をもたらすことがあり、health-knowledge 文脈はしばしば最大の改善を提示。
- Health-Alpaca-LoRa も多くのタスクを改善し、ヘルス系タスクにおけるパラメータ効率の微調整の有効性を示す。
- 単一データセットでの微調整は強い結果を生むことが多いが、複数データセットの Health-Alpaca はタスク間で合理的な一般化を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。