[論文レビュー] Helping the Helper: Supporting Peer Counselors via AI-Empowered Practice and Feedback
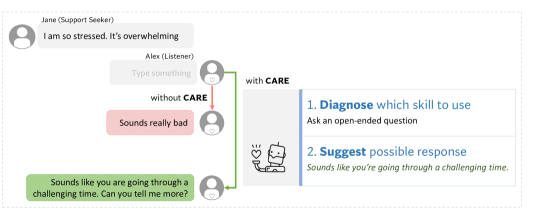
CAREは、同僚カウンセラーを支援する対話型AIツールで、適切なMotivational Interviewing(MI)戦略を予測し、リアルタイムで例示応答を生成します。定量的ログと定性的なユーザー調査を通じて評価されています。
Millions of users come to online peer counseling platforms to seek support. However, studies show that online peer support groups are not always as effective as expected, largely due to users' negative experiences with unhelpful counselors. Peer counselors are key to the success of online peer counseling platforms, but most often do not receive appropriate training.Hence, we introduce CARE: an AI-based tool to empower and train peer counselors through practice and feedback. Concretely, CARE helps diagnose which counseling strategies are needed in a given situation and suggests example responses to counselors during their practice sessions. Building upon the Motivational Interviewing framework, CARE utilizes large-scale counseling conversation data with text generation techniques to enable these functionalities. We demonstrate the efficacy of CARE by performing quantitative evaluations and qualitative user studies through simulated chats and semi-structured interviews, finding that CARE especially helps novice counselors in challenging situations. The code is available at https://github.com/SALT-NLP/CARE
研究の動機と目的
- オンラインの同僚カウンセラーに対する効果的なトレーニングを拡大するという課題に取り組む。
- 人間のカウンセラーを置き換えることなく、初心者に対してリアルタイムで文脈対応のAI支援を提供する。
- システムをMotivational Interviewing(MI)戦略と大規模なカウンセリングデータに基づかせる。
- 定量的なシステムログと定性的なユーザー調査を通じて CARE の有効性を示す。
提案手法
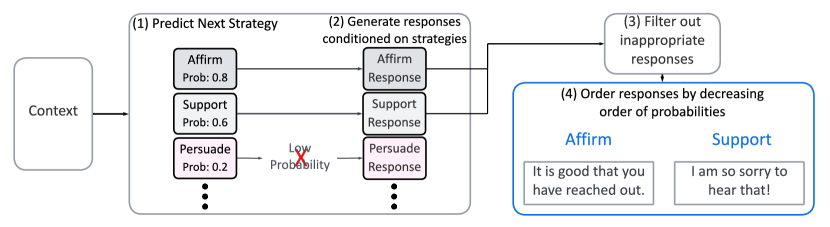
- チャットの直近5つの発話から最も適切なMI戦略を予測するために、バイナリ分類器(BERTベース)を訓練する。
- 予測されたMI戦略に基づいてDialoGPTベースの生成モデルを条件付けし、状況ごとに最大3つの例示応答を生成する。
- 生成された応答をHateBERTベースの不適切な内容分類器でフィルタリングして安全性を確保する。
- バックエンドモデルを7 Cupsを模したフロントエンドインターフェースと統合し、トレーニングチャット中のリアルタイム提案を可能にする。
- トレーニング、検証、評価には7 Cupsデータセット(7C-HQ、7C-MI)を利用する;評価はシステムログ、アンケート、および半構造化インタビューで行う。
実験結果
リサーチクエスチョン
- RQ1CAREは模擬トレーニングチャットにおける同僚カウンセラーの応答の質と有用性を向上させるか?
- RQ2与えられた会話文脈で、BERTベースの分類器が適切なMI戦略をどれだけ正確に予測できるか?
- RQ3戦略条件付き生成モデル(DialoGPT-2、GPT-2、BART)は、適切で安全な例示応答の作成にどの程度性能を発揮するか?
- RQ4初心者および経験豊富な同僚カウンセラーの間で、CAREの有用性と使いやすさはどう認識されているか?
主な発見
- MI戦略分類器は、テストセット7C-MIで全体のF1スコアが0.705を超える。
- 予測された戦略に条件付けられたDialoGPT-2は、生成タスクでGPT-2およびBARTを上回り、セマンティック類似度(BERTScore)が0.87を超え、意図した戦略と約78%の一致(Positive)を達成。
- HateBERTを用いた安全性フィルターは7C-MIテストセットでF1スコア84.21%を達成し、不適切な内容のリコールが高いことを示している。
- 生成品質は戦略によって変動し、Grounding、Open Questions、Introductionで正の割合が高く、Reflection、Persuade、Affirmで低い。
- システムはトレーニングと模擬チャット向けに設計されており、リアルタイム提案と完全な人間監督により、活用される内容をカウンセラーがコントロールできるようになっている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。