[論文レビュー] Hierarchical Neural Story Generation
論文は、前提(premise)と物語の二段階プロセスと融合メカニズム、ゲート付きのマルチスケール自己注意を用いた階層的なストーリ生成アプローチを導入し、コヒーレンスとプロンプト関連性を改善、large WritingPromptsデータセットを用いて評価する。
We explore story generation: creative systems that can build coherent and fluent passages of text about a topic. We collect a large dataset of 300K human-written stories paired with writing prompts from an online forum. Our dataset enables hierarchical story generation, where the model first generates a premise, and then transforms it into a passage of text. We gain further improvements with a novel form of model fusion that improves the relevance of the story to the prompt, and adding a new gated multi-scale self-attention mechanism to model long-range context. Experiments show large improvements over strong baselines on both automated and human evaluations. Human judges prefer stories generated by our approach to those from a strong non-hierarchical model by a factor of two to one.
研究の動機と目的
- 階層性を通じて高レベルな計画を強制することにより、オープンエンドなストーリー生成に動機づけ、課題に取り組む。
- 物語の長距離的一貧を研究するための大規模な prompt-story データセットを作成する。
- 事前学習済みモデルとの融合や、ゲート付きマルチスケール自己注意のようなモデル革新を開発し、プロンプトへの関連性を維持する。
- コヒーレンスとプロンプト準拠性に関して、自動指標と人間評価の双方を用いて改善を評価する。
提案手法
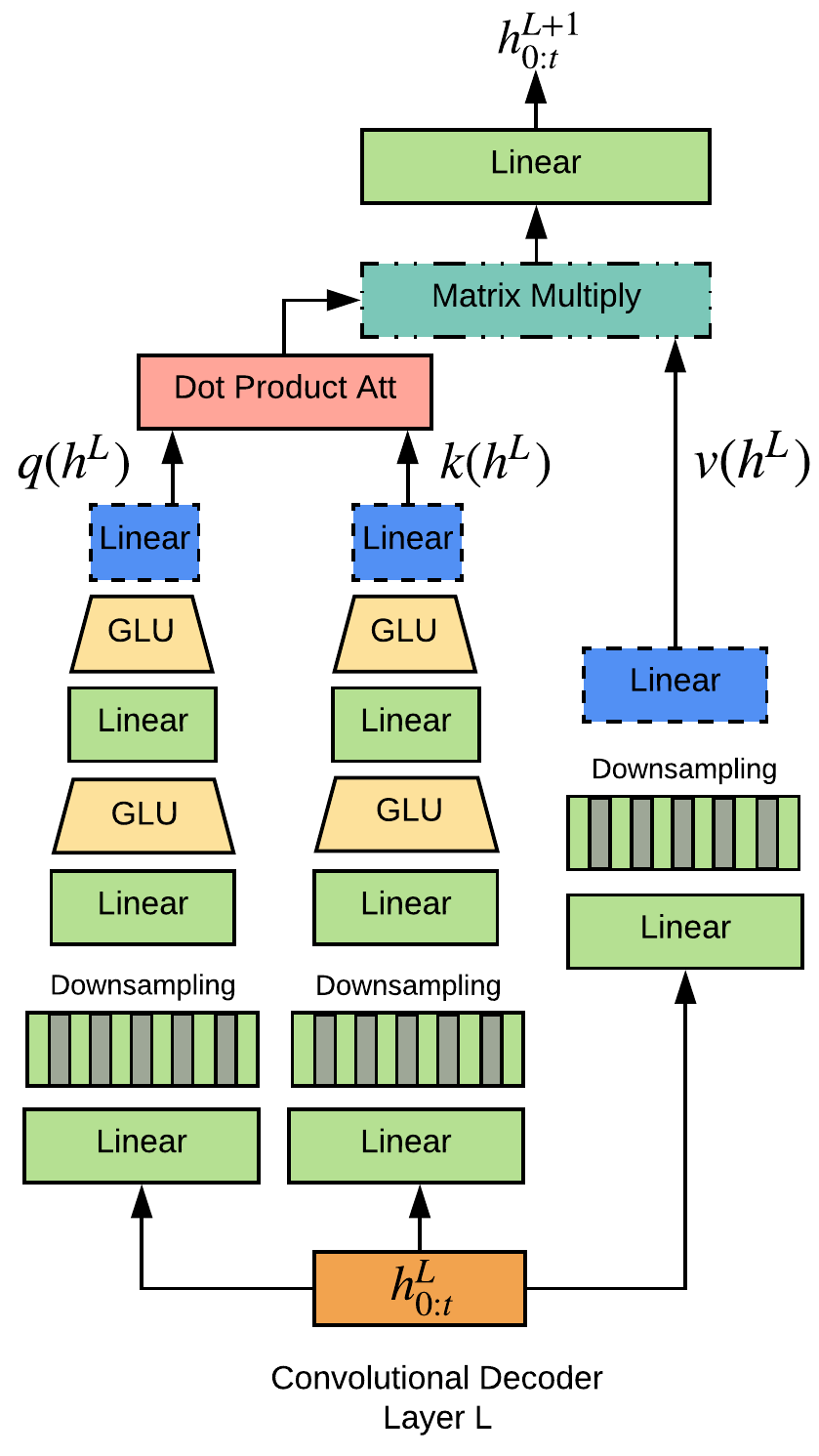
- 二段階生成を構築する:まず畳み込み言語モデルで物語のプロンプト(premise)を生成し、次にこのプロンプトを条件として Conv seq2seq-model を用いて物語を生成する。
- 長文の並列処理を可能にする畳み込み型エンコーダ・デコーダアーキテクチャを採用する。
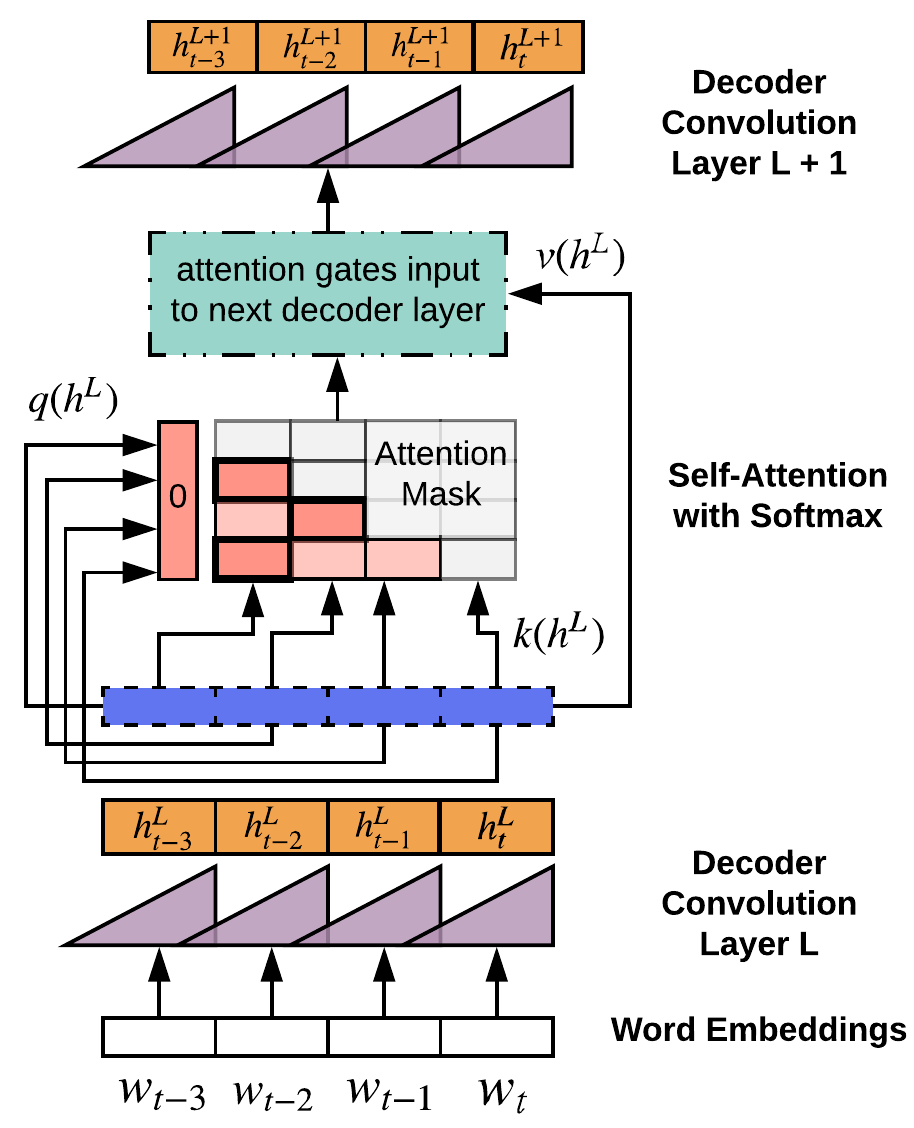
- 異なる時間スケールと past information の選択を可能にする gating を用いた、無限定な文脈をモデル化するゲート付きマルチスケール自己注意を導入する。
- 事前学習済みの seq2seq と第二の seq2seq モデルを組み合わせて、プロンプトへの条件付けを改善する冷 fusion のような融合機構を適用する。
- 生成には top-k サンプリングを用い、プロンプト作成には prompt-language model を用いて、パープレキシティとプロンプト関連性、さらには人間評価を含めて評価する。
実験結果
リサーチクエスチョン
- RQ1階層生成(premise が先、次に物語)により、長編 narratives のコヒーレンスとプロンプトへのトピック遵守が改善されるか。
- RQ2事前学習済みモデルとの融合とゲート付きマルチスケール自己注意は、非階層的ベースラインと比較してプロンプト関連性と長距離の一貫性を改善するか。
- RQ3オープンエンドの prompt-story 設定は、人間評価と自動指標の下でどのように異なるか。
- RQ4提案された注意機構が物語の長距離依存をモデル化する際に与える効果は何か。
主な発見
| Model | Valid Perplexity | Test Perplexity |
|---|---|---|
| Conv seq2seq | 45.27 | 45.54 |
| + self-attention | 42.01 | 42.32 |
| + multihead | 40.12 | 40.39 |
| + multiscale | 38.76 | 38.91 |
| + gating | 37.37 | 37.94 |
- 階層的生成は、非階層的なベースラインに比べて人間の物語選好を大幅に改善する(67.32% vs 32.68%)。
- ゲート付きマルチスケール自己注意と新しい注意機構は、WritingPrompts データセットのパープレキシティを大幅に低減させる(例:テストパープレキシティで gating を用いた場合 45.27 から 37.94 へ)。
- モデル融合(事前学習済みのものの上に第二の seq2seq モデルを学習) は、生成された物語がプロンプトに接続される可能性を大幅に改善し、パラメータ数が少ない Ensemble を上回る。
- 融合は、標準的な seq2seq モデルが捉えるのが難しいプロンプトと物語間の依存関係を学習可能にし、人間評価におけるプロンプト-物語のペアリング精度を向上させる。
- 融合モデルは、トレーニング事例を超えた無制限の生成を可能にしつつ、プロンプトと物語のリンク品質で最近傍探索の性能に匹敵できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。