[論文レビュー] How Does Batch Normalization Help Optimization?
本論文は、BatchNormの有効性は内部共変量シフトを主に低減することよりも、最適化のランドスケープを滑らかにし勾配をより予測可能にすることに起因すると主張する。類似の滑らか化効果は他の正規化スキームでも観測される。
Batch Normalization (BatchNorm) is a widely adopted technique that enables faster and more stable training of deep neural networks (DNNs). Despite its pervasiveness, the exact reasons for BatchNorm's effectiveness are still poorly understood. The popular belief is that this effectiveness stems from controlling the change of the layers' input distributions during training to reduce the so-called "internal covariate shift". In this work, we demonstrate that such distributional stability of layer inputs has little to do with the success of BatchNorm. Instead, we uncover a more fundamental impact of BatchNorm on the training process: it makes the optimization landscape significantly smoother. This smoothness induces a more predictive and stable behavior of the gradients, allowing for faster training.
研究の動機と目的
- 内部共変量シフトの語りだけではなく、なぜ BatchNorm が訓練性能を向上させるのかをより深く理解する動機づけ。
- 経験的にICSとBatchNormの性能の関係を調査する。
- BatchNorm が損失ランドスケープと勾配の予測性に与える滑らか化効果を特徴づける。
- BatchNorm がリプシッツ性と勾配の滑らかさに与える影響を理論的に分析する。
提案手法
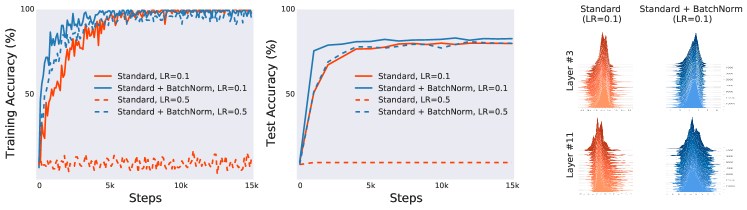
- 標準ベンチマークでCNNと線形ネットワークを用いて、BatchNormありとなしのネットワークを比較する。
- ICS の役割を検証するために、意図的な分布的不安定性を注入する。
- 層間の勾配変化(G および G′)の観点で内部共変量シフトを定義・測定する。
- 勾配方向に沿った損失ランドスケープと勾配予測性を分析する。
- 単一の BN 層を理論的に分析して、リプシッツ性と滑らかさの境界を導出する。
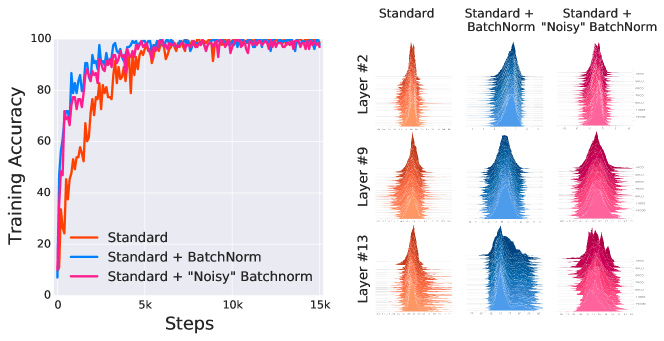
- 滑らか化効果を比較するために代替正規化方式(ℓp-正規化)を探る。
実験結果
リサーチクエスチョン
- RQ1BatchNorm の性能は伝統的に主張されているように内部共変量シフトを低減することに厳密に結びついているのか?
- RQ2BatchNorm は主に最適化ランドスケープを滑らかにし勾配の予測性を向上させるのか?
- RQ3他の正規化スキームは同様の滑らか化と訓練上の利点をもたらすのか?
- RQ4BatchNorm 使用時に観測される経験的改善を説明する理論上の保証とは何か?
主な発見
- BatchNorm ネットワークは、内部共変量シフトが減少していなくても、より安定した訓練とより速い収束を示すことが多い。
- ICS は勾配変化で定義されるが、BatchNorm ネットワークで類似または高くなることがあるにもかかわらず、性能は向上する。
- BatchNorm は最適化問題を再パラメータ化して損失と勾配をよりリプシッツ性にし、勾配方向をより予測可能にする。
- 滑らか化効果は BatchNorm だけでなく他の正規化スキームでも現れ、BN に特有の効果ではないことを示唆している。
- 理論分析は、緩い条件の下で BN が損失勾配のリプシッツ定数を低下させ、勾配の予測性を高めることを示している。
- BN はより平坦な極小値へ収束を促し、一般化を助ける可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。