[論文レビュー] How Does In-Context Learning Help Prompt Tuning?
この論文は、イン-context学習(ICL)、プロンプトチューニング(PT)、および指示プロンプトチューニング(IPT)が5つのテキスト生成タスクにわたってどのように相互作用するかを実証的に分析し、IPTまたはPTがいつ卓越するかと、転移と安定性がどのように振る舞うかを明らかにしている。
Fine-tuning large language models is becoming ever more impractical due to their rapidly-growing scale. This motivates the use of parameter-efficient adaptation methods such as prompt tuning (PT), which adds a small number of tunable embeddings to an otherwise frozen model, and in-context learning (ICL), in which demonstrations of the task are provided to the model in natural language without any additional training. Recently, Singhal et al. (2022) propose ``instruction prompt tuning'' (IPT), which combines PT with ICL by concatenating a natural language demonstration with learned prompt embeddings. While all of these methods have proven effective on different tasks, how they interact with each other remains unexplored. In this paper, we empirically study when and how in-context examples improve prompt tuning by measuring the effectiveness of ICL, PT, and IPT on five text generation tasks with multiple base language models. We observe that (1) IPT does \emph{not} always outperform PT, and in fact requires the in-context demonstration to be semantically similar to the test input to yield improvements; (2) PT is unstable and exhibits high variance, but combining PT and ICL (into IPT) consistently reduces variance across all five tasks; and (3) prompts learned for a specific source task via PT exhibit positive transfer when paired with in-context examples of a different target task. Our results offer actionable insights on choosing a suitable parameter-efficient adaptation method for a given task.
研究の動機と目的
- 全フェインチューニングが実現不可能であることを理由に、大規模言語モデルのパラメータ効率的な適応を動機づける。
- 多様なOOD生成タスクにわたってICL、PT、IPTを比較する。
- IPTがPTを上回る条件とデモンストレーションの類似性の役割を調査する。
- インコントキストデモンストレーションを使用する場合、一つのタスクで学習したソフトプロンプトが他のタスクへ転移可能かを検討する。
提案手法
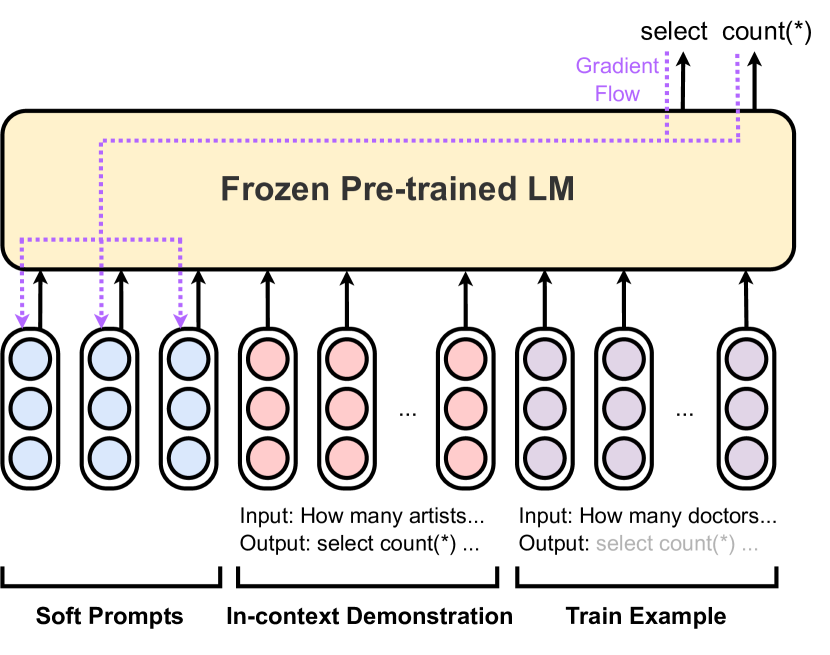
- BLOOM-1.1B、OPT-1.3B、GPT-2-XL-1.5Bを基盤LMとして、5つの言語生成タスクでICL、PT、IPTを経験的に比較する。
- 安定性のため、初期プロンプトの上に2つのフィードフォワード層を置いて、PTとIPTにはソフトプロンプト埋め込みを使用する。
- 高密度検索(最近傍法)でインコントキストデモンストレーションを取得し、テスト例ごとに1つのデモンストレーションを評価する。
- PT/IPTをランダムに初期化したプロンプトで訓練し、 dev loss で評価し、AdamW最適化で3回の実行の平均を報告する。
- インコントキストデモンストレーションとテスト入力の類似性がIPT対PTの性能に与える影響を評価する。
- ソースタスクのプロンプトとターゲットタスクのインコントキストデモンストレーションを組み合わせて、タスク間転移を探る。
実験結果
リサーチクエスチョン
- RQ1IPTとPTはどのような条件でICLを上回る(あるいは超える)のか、アウト・オブ・ディメイン生成タスクにおいて。
- RQ2取得されたインコントキストデモンストレーションとテスト入力の類似性がIPT対PTの性能にどのように影響するか。
- RQ3ソフトプロンプトのトークン数などのハイパーパラメータを調整した際、PTの分散をIPTが低減できるか。
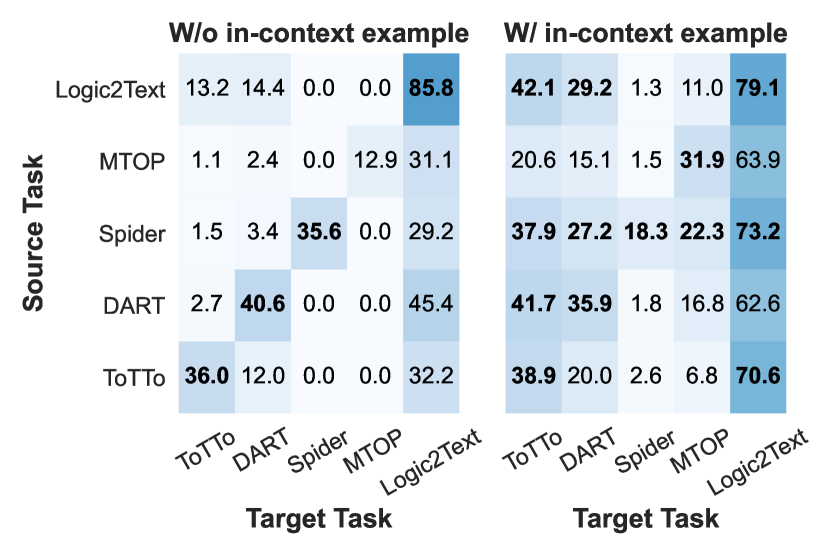
- RQ4ソースタスクで学習したソフトプロンプトが、ターゲットタスクのデモンストレーションと組み合わせると新しいターゲットタスクへ有益に転移するか。
- RQ5取得デモンストレーションを用いた場合、5つの異なるデータ-to-text、logic-to-text、semantic parsingタスクにおける効果はどうなるか。
主な発見
- IPTとPTは5つのタスクすべてでICLを上回り、少数のパラメータを訓練することでもアウト・オブ・ドメインタスクに有効であることを示す。
- PTとIPTのいずれにも普遍的な勝者はなく、タスクと設定(例:プロンプト埋め込みの数)によって性能が変動する。
- インコントキストデモンストレーションがテスト入力と高度に類似している場合(特にToTToで)、IPTがPTを上回る。
- PTは調整可能なパラメータ数が増えると高い分散を示す一方、IPTは分散を低減し、プロンプトトークン数に対する感度が低い。
- ソースタスクで学習したソフトプロンプトが、ターゲットタスクのデモンストレーションと組み合わせると新しいターゲットタスクへ有益に転移し、いくつかのクロス・タスク設定でICLを上回る。
- IPTは一般にPTと比べてハイパーパラメータに対してより安定した収束と頑健性を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。