[論文レビュー] How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
この論文は、モデルサイズ(6.7B–65B)とベース言語モデルを横断してオープン instruction-tuning データセットを体系的に評価し、すべてのタスクに最適なデータセットは存在しないこと、ベースモデルの品質が重要であること、彼らの最良のオープンモデル(Tülu)は平均的にはChatGPT/GPT-4に劣ることを示す。彼らはモデル、データ、評価フレームワークを公開する。
In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce Tülu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 87% of ChatGPT performance, and 73% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B Tülu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.
研究の動機と目的
- オープンデータセットでのinstruction-tuning が様々なモデル能力(事実知識、推論、多言語性、コーディング、安全性、オープンエンドなinstruction遵守)に与える影響を評価する。
- オープン instruction tuning に用いられるリソースの強み・弱点を特定するため、幅広いベースモデルと instruction データセットでの性能を比較する。
- モデルベース評価とベンチマークベース評価がモデル能力の開示に整合するかを検討する。
- 多様なオープンリソースから構築された最高性能のオープン instruction-tuned モデル群(Tülu)を提案・評価する。
提案手法
- 様々な instruction データセットを共通のチャットボット形式に統一し、teacher-forcingとトークンレベルの損失マスキングを用いてdecoder-only LMを訓練する。
- 12のinstructionデータセット( manual, synthetic, distilled sources を含む)にわたり、ベースLMとして LLaMa, LLaMa-2, OPT, Pythia、サイズは 6.7B–65B で訓練する。
- Tülu モデルを訓練するために Human データと Human+GPT データの2つのデータ混合を作成し、混合の影響を比較する。
- MMLU、GSM、BBH、TyDiQA、Codex-Eval、AlpacaEval、ToxiGen、TruthfulQA などの多面的な評価スイートと、モデルベース(GPT-4アノテーター)および人間の評価を用いてモデルを評価する。
- データセットの選択、ベースモデルの品質、データ混合がタスクと評価モダリティを横断して性能に与える影響を分析する。)

実験結果
リサーチクエスチョン
- RQ1instruction-tuning データセットは、事実知識、推論、多言語性、コーディング、およびオープンエンドな instruction遵守といった特定のモデルスキルにどのような影響を与えるか。
- RQ2多様なデータセットを組み合わせると全体で最高の性能を得られるのか、それともタスク固有のデータセットが特定の評価で支配的になるのか。
- RQ3ベースモデルの品質(サイズと事前学習データ)は、instruction-tuning データとどのように相互作用して性能に影響を与えるか。
- RQ4モデルベース評価と人間評価が、ベンチマークベース評価とモデル能力を反映する際にどの程度整合するか。
- RQ5オープンな instruction-tuned モデルと proprietary モデル(ChatGPT、GPT-4)との性能ギャップは評価設定全体でどれくらいか。
主な発見
- 異なる instruction データセットは異なる能力を高める;すべてのタスクで優れた単一データセットは存在しない。
- より大きなベースモデルは、instruction tuning 後に一般にパフォーマンスが向上し、ベースモデルの品質が支配的な要因である。
- 高品質なオープンデータセットの混合(Tülu)はベンチマーク全体の平均性能を最も高くするが、彼らの設定ではChatGPTやGPT-4には平均的に勝てない。
- 多様なデータでファインチューニングされた65Bのオープンモデルでも、独自モデルにはまだ及ばない。残るギャップを示している。
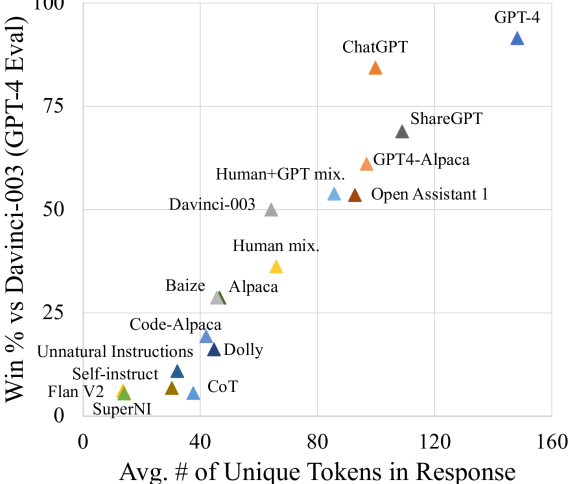
- モデルベースの好感度シグナルは生成長と相関し、真の能力よりも評価の偏りを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。