[論文レビュー] How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
この論文はGPTモデル(ChatGPT、text-davinci-003、text-davinci-002)を18の言語方向の機械翻訳に対して評価し、高資源言語での強力な性能、低資源言語での限られた能力、 prompting戦略、ドキュメントレベル翻訳、GPT+NMTハイブリッドアプローチの利点を示します。
Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
研究の動機と目的
- 高資源言語と低資源言語の翻訳品質をGPTモデルで評価する。
- prompting戦略(ゼロショット、ファew-shot)と翻訳性能への影響を探る。
- ドキュメントレベルの翻訳能力とドメインシフト下でのロバスト性を評価する。
- GPTモデルを最先端の研究・商用システムと比較する。
- GPTと従来のNMTシステムを組み合わせる潜在的な利点を調査する。
提案手法
- GPTバリアント(text-davinci-002、text-davinci-003、ChatGPT)をWMT-BestおよびMicrosoft Translatorと18言語ペアで比較する。
- ゼロショットおよびファew-shot promptingを用いて文脈内学習効果を評価する。
- 評価にはニューラルMT指標(COMET-22、COMETkiwi)と語彙指標(BLEU、ChrF)を用い、ドキュメントレベルの適応(Doc-COMETkiwi)を追加する。
- スライディングウィンドウの重複を介してドキュメントレベル評価用にCOMET-kiwiを適応する(Doc-COMETkiwi)。
- 指標ベースの評価を補完するための人間評価を実施する。
- 翻訳結果に対するプロンプト設計(品質と関連性)とその影響を分析する。
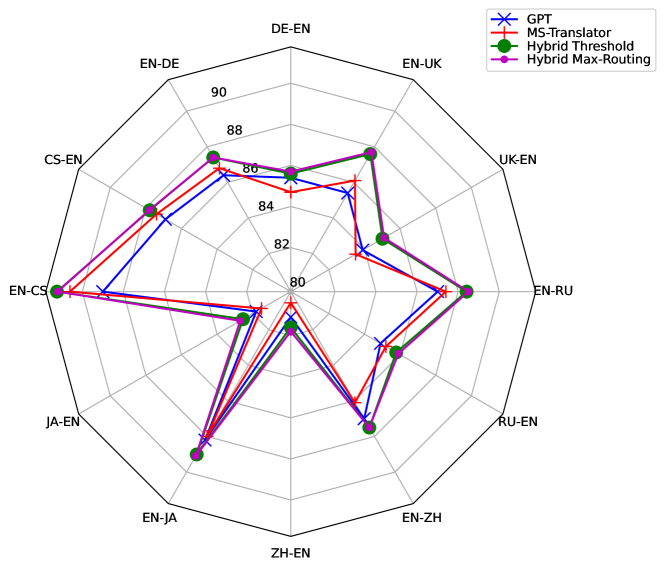
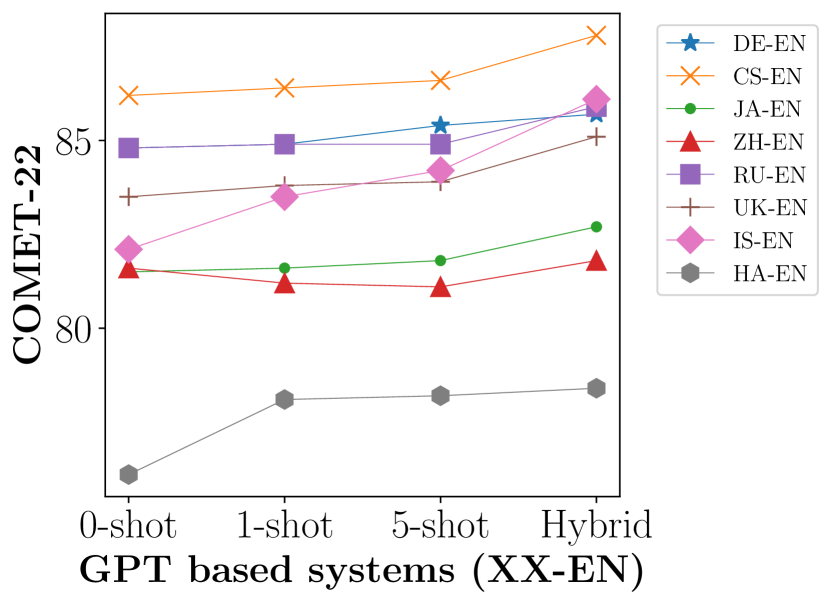
実験結果
リサーチクエスチョン
- RQ1GPTモデルは diverseな言語ペアに対して、最先端の研究・商用システムと比較して機械翻訳でどのように性能を発揮するか?
- RQ2ゼロショットとファew-shot、ショットの品質と関連性など、 prompting戦略がGPT翻訳品質に与える影響は?
- RQ3GPTモデルはドキュメントレベルで効果的に翻訳できるか、コンテキストは性能にどう影響するか?
- RQ4GPT翻訳はドメインシフトや非英語中心の翻訳にどれだけロバストか、GPTは従来のNMTシステムを補完するか?
- RQ5NMTと比較した場合のGPT翻訳の特徴と限界、アーティファクトや潜在的な跨言語利点は?
主な発見
- 高資源言語ではGPTモデルの翻訳品質は非常に競合力があるが、低資源言語では能力が限定的。
- 特に few-shot の高品質なショットは、英語から他言語への翻訳などの方向で性能を向上させることがある。
- GPTを用いたドキュメントレベル翻訳はより広い文脈を活用でき、適切な評価指標を用いれば、いくつかの基準系よりも近づくまたは上回る可能性がある。
- GPTモデルと従来のNMTシステムを組み合わせたハイブリッドアプローチは翻訳品質をさらに高める可能性がある。
- 人間評価と詳細な分析はGPT翻訳の長所と短所を明らかにし、アーティファクトパターンや跨言語の挙動について洞察を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。