[論文レビュー] How well do Large Language Models perform in Arithmetic tasks?
本論文は MATH 401 を紹介します。これはLLMsの数値計算能力を多様な演算で評価する算術データセットであり、GPT-4と ChatGPT が最高の精度を達成し、トークン化・事前学習・プロンプト・スケーリングなどの要因を分析します。
Large language models have emerged abilities including chain-of-thought to answer math word problems step by step. Solving math word problems not only requires abilities to disassemble problems via chain-of-thought but also needs to calculate arithmetic expressions correctly for each step. To the best of our knowledge, there is no work to focus on evaluating the arithmetic ability of large language models. In this work, we propose an arithmetic dataset MATH 401 to test the latest large language models including GPT-4, ChatGPT, InstrctGPT, Galactica, and LLaMA with various arithmetic expressions and provide a detailed analysis of the ability of large language models. MATH 401 and evaluation codes are released at \url{https://github.com/GanjinZero/math401-llm}.
研究の動機と目的
- LLMsにおける数学および推論能力の代理として算術能力を評価する必要性を動機付ける。
- 整数、小数、無理数、長い式にわたる算術評価スイート MATH 401 を紹介する。
- アーキテクチャの選択とトレーニングデータがLLMsの算術性能に与える影響を分析する。
- 算術結果を改善するためのプロンプト、システムメッセージ、プロンプティング戦略の指針を提供する。
提案手法
- 加算、減算、乗算、除算、べき乗、三角関数、対数、長い括弧付き式を含む401の算術式を構築する。
- さまざまなプロンプトと入力形式の下で、GPT-4、ChatGPT、InstructGPT、Galactica、LLaMA、OPT、Bloom など幅広いLLMを評価する。
- 正確さ、相対誤差、非数字比率を指標として用い、小数点以下4桁の丸めとデコード後の数値の特定の取り扱いを行う。
- 算術性能に対するトークン化の影響、コード・LaTeXソースの事前学習データ、命令調整、RLHFを比較する。
- 補間/外挿、スケーリング則、思考過程(COT)の影響、および文脈内学習(ICL)が算術タスクに与える影響を検討する。
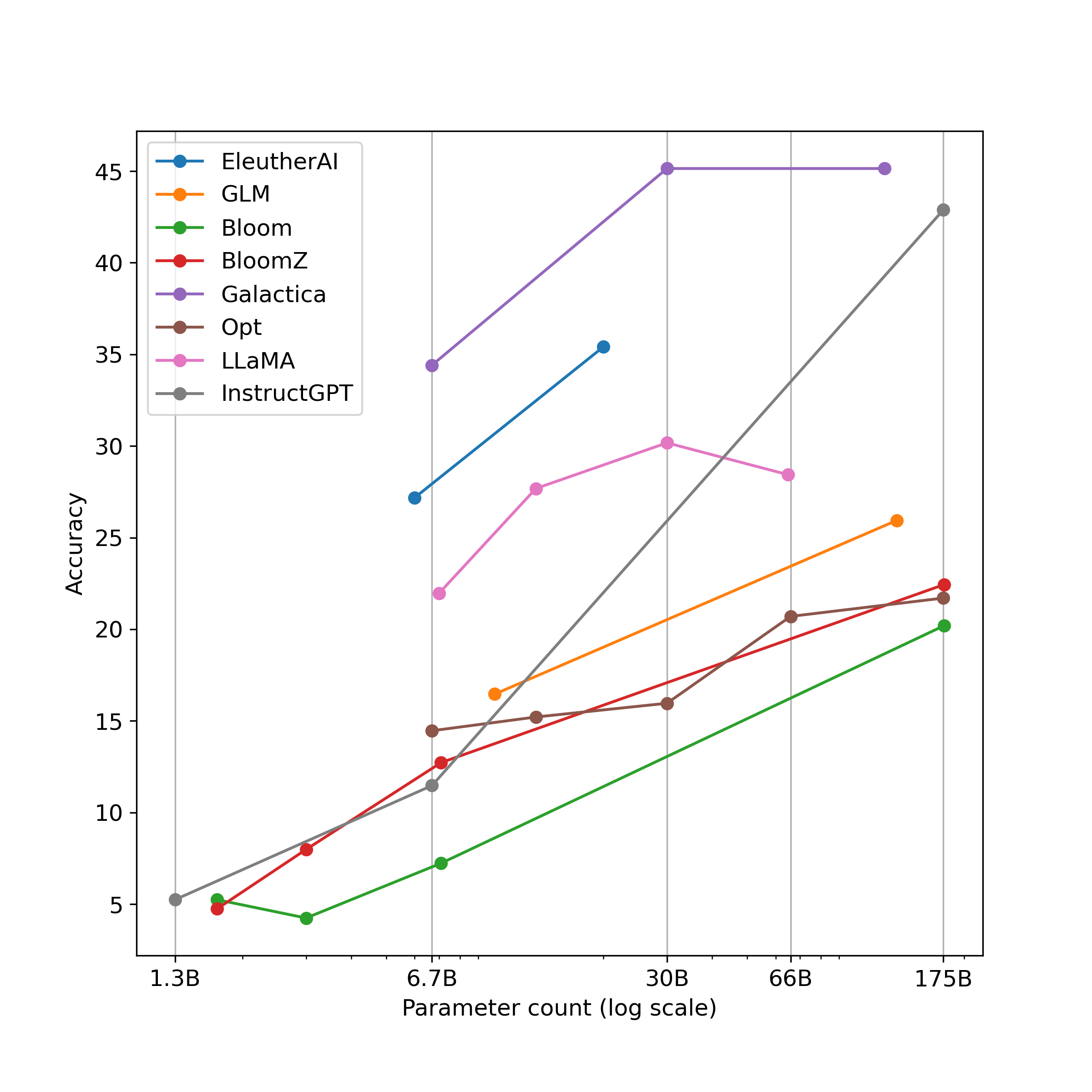
実験結果
リサーチクエスチョン
- RQ1現在の大規模言語モデルは、さまざまな演算子と数値形態にわたる算術タスクでどの程度の能力を持つか。
- RQ2トークン化、トレーニングデータ、プロンプト、スケーリングといった要因がLLMsの算術性能にどのように影響するか。
- RQ3思考過程プロンプトやシステムレベルプロンプトは算術精度を有意に改善するか。
- RQ4命令調整とICLは算術能力を有意に高めるか、またモデルサイズは結果にどう影響するか。
- RQ5モデルは易しい算術と難しい算術グループでどうパフォーマンスし、長い式へ外挿できるか。
主な発見
- GPT-4とChatGPTは、算術タスク全般において他のすべてのモデルを大きく上回る。
- 除算、十進数を用いたべき乗、三角法、対数は多くのモデルにとって依然として難しく、大きな数値と長い式はGPT-4とChatGPTの方がよりうまく扱える。
- 数字を桁ごとに分割するなどのトークン化戦略は算術の正確さに顕著な影響を与える;数字を桁に分割するモデルは異なる挙動を示す傾向がある。
- 命令調整とRLHF(InstructGPTおよびChatGPTのような)は、初期の事前学習済みまたはSFTモデルに比べ算術能力を向上させる。
- プロンプトは重要:LaTeXや数式テキストのプロンプトは多くのモデルで一般により良い結果をもたらす;システムプロンプトはChatGPTの精度を大幅に向上させ、非数字のデコードを減らす。
- COTプロンプトは算術性能を一貫して改善するとは限らない;単純な計算プロンプトは長い式でより良い結果を生むことがある。
- スケーリングは一定の限界まで効果がある;約30Bパラメータを超えるといくつかのモデル(例:Galactica)で利得が頭打ちになる一方、GPT-4/ChatGPTは長い式に強い能力を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。