[論文レビュー] How well do LLMs cite relevant medical references? An evaluation framework and analyses
本論文は SourceCheckup を紹介し、LLM が引用する情報源が医療表現をどの程度裏付けるかを自動的に評価するパイプラインを提案し、上位モデル全体で支援のギャップを顕著に発見し、専門家の注釈付きの医療QAデータセットを公開します。
Large language models (LLMs) are currently being used to answer medical questions across a variety of clinical domains. Recent top-performing commercial LLMs, in particular, are also capable of citing sources to support their responses. In this paper, we ask: do the sources that LLMs generate actually support the claims that they make? To answer this, we propose three contributions. First, as expert medical annotations are an expensive and time-consuming bottleneck for scalable evaluation, we demonstrate that GPT-4 is highly accurate in validating source relevance, agreeing 88% of the time with a panel of medical doctors. Second, we develop an end-to-end, automated pipeline called extit{SourceCheckup} and use it to evaluate five top-performing LLMs on a dataset of 1200 generated questions, totaling over 40K pairs of statements and sources. Interestingly, we find that between ~50% to 90% of LLM responses are not fully supported by the sources they provide. We also evaluate GPT-4 with retrieval augmented generation (RAG) and find that, even still, around 30\% of individual statements are unsupported, while nearly half of its responses are not fully supported. Third, we open-source our curated dataset of medical questions and expert annotations for future evaluations. Given the rapid pace of LLM development and the potential harms of incorrect or outdated medical information, it is crucial to also understand and quantify their capability to produce relevant, trustworthy medical references.
研究の動機と目的
- 自動化されたフレームワークを開発し、医療Q&AにおけるLLMの出典属性を評価する。
- 専門家による注釈を含む医療の質疑応答データセットを作成し、出典検証を行う。
- GPT-4 RAG/API、Claude v2.1、Mistral Medium、Gemini Pro など、上位モデルの出典支援を評価する。
- URL の有効性、文レベルの支援、応答レベルの支援の指標を定量化する。
- 信頼できる医療AIのための未来のベンチマーキングを可能にするよう、厳選データをオープンソースにする。
提案手法
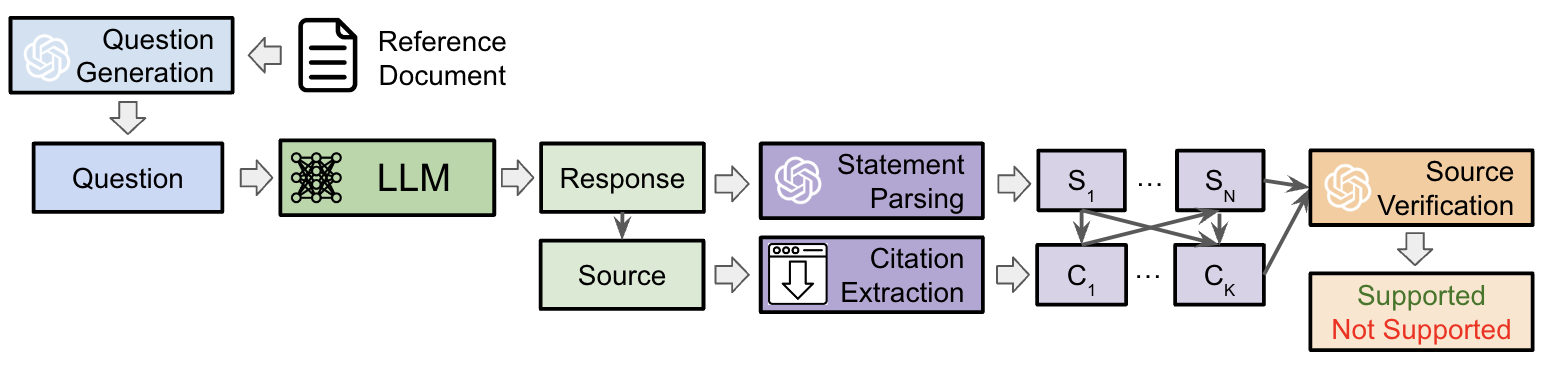
- 四部構成の SourceCheckup パイプライン:Question Generation、LLM Question Answering、Statement and URL Source Parsing、Source Verification。
- GPT-4 を用いて 1200 ページの参照元(Mayo Clinic、UpToDate、Reddit r/AskDocs)から新規の医療質問を生成。
- LLMs は本文と引用URLを含む回答を提供し、回答を個別の文に分解。
- URL をダウンロードしてプレーンテキストに変換;内容は GPT-4 の 128K トークン制限に合わせて切り詰め。
- Statement-source ペアは自動的に Source Verification モデル(GPT-4)によって支援の有無が評価される。
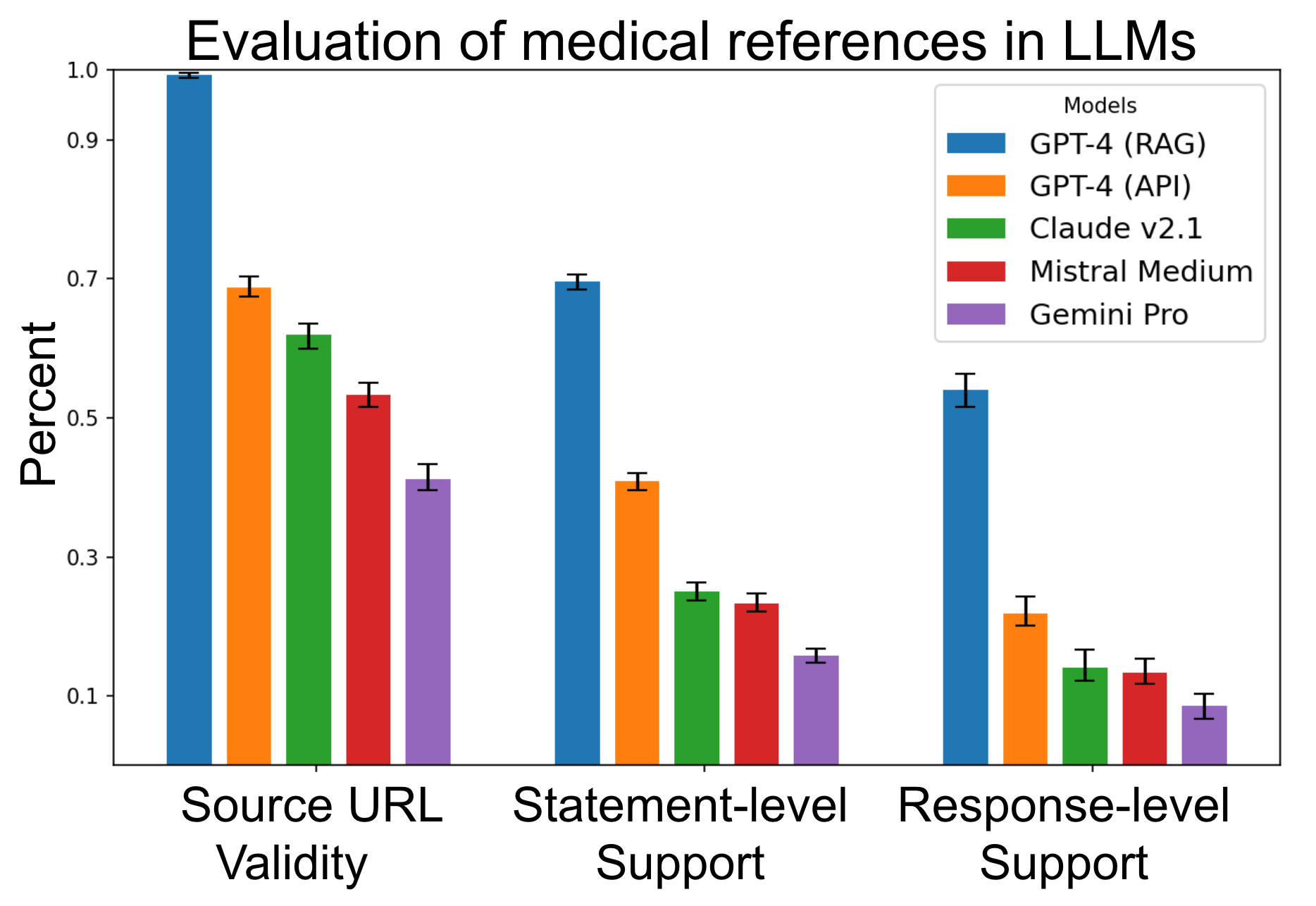
- 三つの指標:Source URL Validity(200 OK)、Statement-level support(どれかのソースが文を支援)、Response-level support(全ての文が支援されていること)。
- Expert validation: GPT-4 automated tasks validated against US-licensed doctors; 88% agreement on source relevance.
実験結果
リサーチクエスチョン
- RQ1LLM が生成する医療文が、提供された引用の中にどの程度裏付けとなる出典を持っているのか?
- RQ2LLM は自分の主張を実際に裏付ける有効で取得可能なURL をどのくらいの頻度で提供するか?
- RQ3Retrieval-augmented generation (RAG) は出典支援を改善するか、どの程度改善するか?
- RQ4出典の支援は質問ソース(Mayo Clinic、UpToDate、Reddit r/AskDocs)によってどう異なるか?
- RQ5トップLLM が一般的に引用する出典の質と構成はどうなっているか?(ドメイン、USベースか非US、ペイウォール)
主な発見
- 上位5モデルのうち、回答の50%から90%が提供された出典によって完全には裏付けられていない。
- RAG を備える GPT-4 は最も良い引用能力を示すが、回答レベルで完全に裏付けられているのは約54%に留まる。
- GPT-4 API は文レベルの支援が高く、URL の有効性は約70%超、文レベル支援も70%超を示すケースがある。
- すべての API エンドポイントモデルは URL の使用が顕著だが、完全な支援率は低く、Gemini Pro は約7% が完全に裏付けられている。
- RAG は URL の有効性と URL の幻視を減らすのに役立つが、検証タスクは依然として難しいとの専門家の見解。サンプルペアでは医師は Source Verification モデルと約86-96%の一致を示す。
- 最も引用される出典は US ベース(.org/.gov)で Mayo Clinic、NIH、CDC などからのもので、ペイウォール/停止ページは稀である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。