[論文レビュー] HuatuoGPT, towards Taming Language Model to Be a Doctor
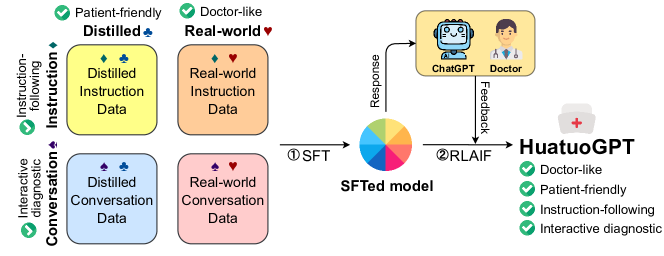
HuatuoGPTはChatGPTで蒸留したデータと実世界の医師データを融合し、AIフィードバックからのRLを用いて中国語医療LLMを作成。オープンソースの競合を上回り、医療相談においてChatGPTと肩を並べることもしくは上回ることが多い。
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both extit{distilled data from ChatGPT} and extit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.
研究の動機と目的
- グローバルな医療アクセス格差を縮小するために、オープンソースでプライベート展開可能な医療LLMの推進。
- 蒸留されたChatGPTデータと実世界の医師データを組み合わせた2段階の訓練パイプラインを提案。
- RLAIF(AIフィードバックからの強化学習)を導入し、モデル出力を指示遵守と医師のような推論の両方に整合させる。
- 複数の医療データセットにわたる自動評価と人間評価を組み合わせた包括的な評価スキームを確立。
提案手法
- ハイブリッドデータSFT:指示データと実世界の医師との会話で訓練し、医師のようで患者に優しい振る舞いを付与。
- 蒸留データの組み込み:ChatGPT生成の医療指示と会話を活用して指示遵守と流暢さを向上。
- 報酬モデル:大規模言語モデルのスコアを用いて情報性、一貫性、事実性を捉える報酬モデルを訓練。
- AIフィードバックによる強化学習(RLAIF):KLペナルティ付きポリシー更新で、ChatGPTと医師のメリットの両方に整合させるよう最適化。
- ベースモデルと設定:BLOOMZ-7b1-mtバックボーン;8枚のA100 GPUでのマルチステージ訓練、特定のLR/batch/context設定、一般的な対話能力のための追加中国語データ。
実験結果
リサーチクエスチョン
- RQ1実世界の医師データと蒸留されたChatGPTデータを組み合わせると、医師のような診断や患者向けのコミュニケーションは改善されるか。
- RQ2AIフィードバックからの強化学習(RLAIF)は、純粋なSFTよりも医療LLMの出力を専門的な診断品質と患者の安全性により良く整合させられるか。
- RQ3HuatuoGPTは、中国語医療ベンチマークおよびGPT-4評価の単回・多回対話シナリオで、ベースラインと比べどう性能を示すか。
- RQ4実世界データを活用した場合、HuatuoGPTは多くの医療相談タスクで教師モデルChatGPTを上回ることができるか。
主な発見
| Dataset | Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | GLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | Distinct-1 | Distinct-2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| cMedQA2 | HuatuoGPT | 25.37 | 13.16 | 7.39 | 4.25 | 8.30 | 27.75 | 7.31 | 17.36 | 0.74 | 0.93 |
| webMedQA | HuatuoGPT | 24.61 | 12.84 | 7.23 | 4.19 | 7.73 | 27.38 | 7.09 | 17.66 | 0.71 | 0.93 |
| Huatuo-26M | HuatuoGPT | 25.16 | 13.21 | 7.54 | 4.40 | 8.37 | 27.76 | 7.45 | 17.99 | 0.73 | 0.93 |
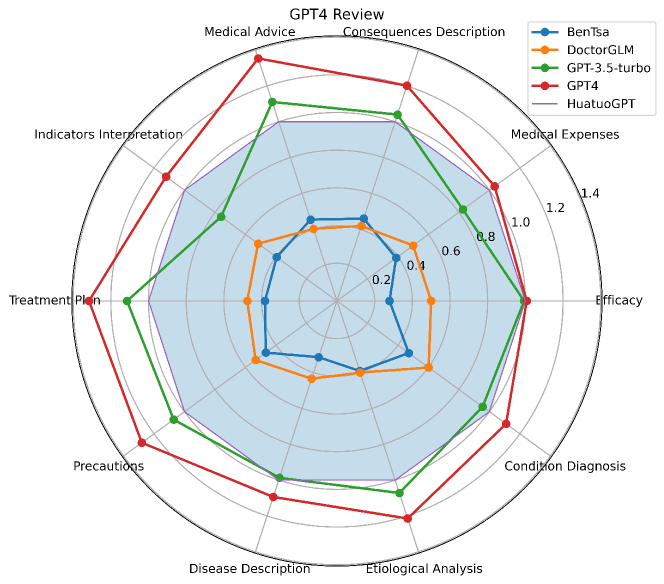
- HuatuoGPTは中国語医療分野のGPT-4・人間評価・医療ベンチマークにおいて、オープンソースLLMの中で最先端の結果を達成。
- 多くのケースで、実世界データとRLAIFを用いたHuatuoGPTは教師モデルのChatGPTを上回る。
- HuatuoGPTはSOTAをcMedQA2、webMedQA、Huatuo-26Mベンチマークで達成。
- 自動(GPT-4)および手動評価は、HuatuoGPTの医師のような正確さ、対話的質問、患者に優しい応答を裏付ける。
- 複数部門にわたる単回・多回の評価で、BenTsao、DoctorGLM、GPT-3.5-turboを一貫して上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。