[論文レビュー] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
HuBERTは、マスクされた音声特徴からK平均クラスタリングされたユニットを予測する自己教師付き音声表現学習手法を提案する。オフラインのクラスタリング手順により偽ラベルを生成し、マスクされた領域でのみ予測損失を適用することで、頑健な音声的および言語的表現を学習する。10億パラメータを持つモデルを用いて、Librispeech dev-otherでは最大19%、test-otherでは13%のWER低減を達成し、最先端の性能を実現した。
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
研究の動機と目的
- 自己教師付き音声表現学習の課題に取り組むこと:重複する音声ユニット、事前に定義された語彙なし、長さが可変なユニット。
- 事前学習中に言語的アノテーションに依存せずに頑健な表現を学習する手法を開発すること。
- 連続的な音声特徴に対してBERTに類似したマスクされた予測目的を用いて、下流のASRタスクにおける汎化性と性能を向上させること。
- クラスタリングの品質、ハイパーパrameter、アンサンブル手法がモデル性能に与える影響を調査すること。
提案手法
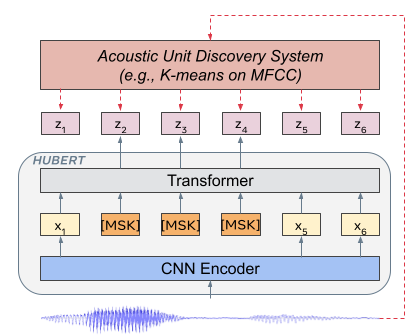
- MFCCまたはHuBERT特徴に対してオフラインのk平均クラスタリングを適用し、マスクされた予測のための離散的ターゲットユニットを生成する。
- モデルは、マスクされた音声フレームのクラスタ割り当てを予測するためのBERTに類似したトランスフォーマー構造を用い、損失はマスクされた領域でのみ計算される。
- 予測タスクにより、マスクされたユニットを未マスクの文脈を用いて再構成することで、文脈に依存した表現を学習するよう強制される。
- 以前のモデル反復からの潜在表現を用いて、クラスタ割り当てを繰り返し精錬することで、ターゲット品質を向上させる。
- 段階的な訓練プロセスを用い、反復ごとにより正確なクラスタターゲットを用いることで、表現品質を向上させる。
- 一般化性と収束性を最適化するために、効果的バッチサイズとマスキング確率を調整する。
実験結果
リサーチクエスチョン
- RQ1マスクされたフレームのみを予測することで、すべてのフレームや未マスクフレームを予測する場合と比較して、自己教師付き音声表現学習にどのように寄与するか?
- RQ2クラスタリング品質がモデル性能に与える影響は何か、特にノイズが多いまたは低品質なクラスタ割り当てを用いる場合にどうなるか?
- RQ3異なる特徴タイプや設定で訓練されたk平均モデルのアンサンブルを用いることで、表現品質にどのような影響があるか?
- RQ4マスキング確率やバッチサイズといったハイパーパrameterの中で、HuBERTの性能に最も顕著な影響を与えるものは何か?
- RQ5クラスタ割り当ての繰り返し精錬が、さまざまな事前学習データスケールにおいて一貫した性能向上をもたらすか?
主な発見
- Librispeech(960時間)およびLibri-light(6万時間)の両ベンチマークにおいて、10分から960時間までのあらゆるファインチューニングサブセットで、wav2vec 2.0の最先端性能と同等またはそれを上回る性能を達成した。
- 10億パラメータを持つモデルを用いて、より挑戦的なLibrispeech dev-otherセットでは19%の相対的WER低減、test-otherでは13%を達成した。
- マスクされたフレームのみを予測することで、すべてのフレームや未マスクフレームを予測する場合と比較して顕著に高い性能が得られ、特にクラスタリング品質が低い場合に顕著であった。
- 長期間の学習(最大80万ステップ)により一貫した性能向上が得られ、10時間分のLibri-lightスプリットで最良のWER11.68%を達成した。
- 異なる特徴タイプや設定で訓練された複数のk平均モデルをアンサンブル化することで、単一のクラスタリング設定よりも優れた性能が得られた(例:スプライスドMFCCにプロダクト量子化を適用)。
- 最適なマスキング確率は8%であり、バッチサイズを増加させることでモデルの一般化性能が顕著に向上した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。