[論文レビュー] Identity Mappings in Deep Residual Networks
本論文は、恒等的スキップ接続と恒等的な加算後活性化が非常に深いResNetで直接的な前方および後方情報伝播を可能にする仕組みを分析し、プレアクティベーション残差ユニットを提案し、CIFARおよびImageNetで極めて深いネットワークのトレーニングと一般化を改善することを実証します。
Deep residual networks have emerged as a family of extremely deep architectures showing compelling accuracy and nice convergence behaviors. In this paper, we analyze the propagation formulations behind the residual building blocks, which suggest that the forward and backward signals can be directly propagated from one block to any other block, when using identity mappings as the skip connections and after-addition activation. A series of ablation experiments support the importance of these identity mappings. This motivates us to propose a new residual unit, which makes training easier and improves generalization. We report improved results using a 1001-layer ResNet on CIFAR-10 (4.62% error) and CIFAR-100, and a 200-layer ResNet on ImageNet. Code is available at: https://github.com/KaimingHe/resnet-1k-layers
研究の動機と目的
- Skip connections が非常に深い残差ネットワークにおける情報伝搬をどのように促進するかを動機づけ、分析する。
- 最適化と一般化に対するショートカットのタイプと活性化配置の影響を調査する。
- 加算後活性化を恒等とする新しい残差ユニット(プレアクティベーション)を提案し、最適化を容易にし性能を向上させる。
- CIFAR-10/100およびImageNet上で超深層ネットワークの最先端または競合的な結果を示す。
- 最適化の容易さとモデル容量のバランスを取るための深いResNet設計に関する実用的なガイドラインを提供する。
提案手法
- 2つの恒等条件下でのフォワードおよびバックワード伝播特性を導出する。1つは恒等スキップ接続 h(x)=x、もう1つは恒等後加算活性化 f(y)=y。
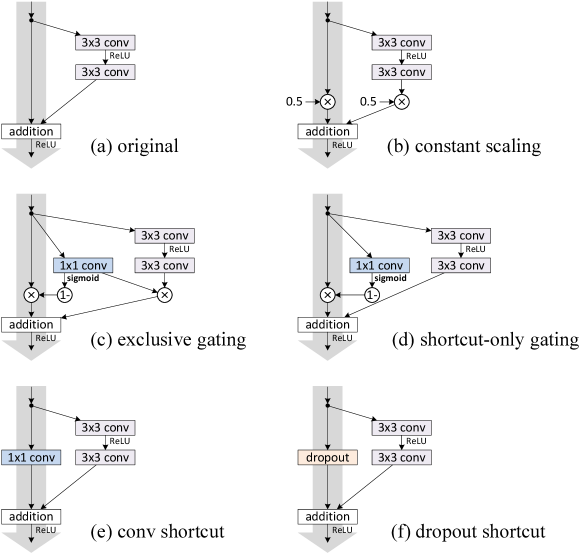
- 非恒等ショートカット成分(スケーリング、ゲーティング、1x1畳み込み、ドロップアウト)の影響を理論式とアブレーション実験を用いて分析する。
- 活性化を重み層の前に移動させ、加算後活性化を実質的に恒等とするプレアクティベーション残差ユニットを導入する。
- CIFAR-10/100でResNet-110/164/1001アーキテクチャとImageNetでResNet-152/200の変種を用いて変種を実験的に比較する。
- BN/ReLU の配置が加算の前後どちらにあるかなど、トレーニングとアーキテクチャのガイドラインを提供する。
- 提案設計を裏付ける性能指標とトレーニングダイナミクスを報告する。
![Figure 1: Left : (a) original Residual Unit in [ 1 ] ; (b) proposed Residual Unit. The grey arrows indicate the easiest paths for the information to propagate, corresponding to the additive term “ $\mathbf{x}_{l}$ ” in Eqn.( 4 ) (forward propagation) and the additive term “1” in Eqn.( 5 ) (backward](https://ar5iv.labs.arxiv.org/html/1603.05027/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1恒等スキップ接続と恒等後加算活性化は深いResNetにおける前方信号伝播にどのような影響を与えるのか?
- RQ2非恒等ショートカット成分(スケーリング、ゲーティング、1x1畳み込み、ドロップアウト)は最適化と一般化にどのような影響を与えるのか?
- RQ3プレアクティベーション残差ユニットは ultra-deep なネットワークの訓練を可能にし、元の残差ユニットと比較して一般化を改善できるのか?
- RQ4活性化配置とBNのタイミング(プレ-対ポスト活性化)はCIFAR-10/100とImageNetで性能にどう影響するか?
- RQ5訓練が容易で精度が向上する非常に深いResNetを構築するための実践的ガイドラインは何か?
主な発見
- 恒等スキップ接続と恒等後加算活性化は、層間での直接的な信号伝搬を許すことで最適化を大幅に緩和する。
- 非恒等ショートカット成分は一般に情報フローを妨げ、訓練ダイナミクスや最終性能を悪化させることが多い。
- プレアクティベーション残差ユニット(活性化関数を重み層より前に適用)により、非常に深いネットワーク(例:1001層)の訓練を可能にし、CIFAR-10/100での一般化を改善し、ImageNetで競争力のある結果を示す。
- CIFAR-10で、1001層のResNetはテスト誤差4.62%を達成(プレアクティベーション変種が最良の結果);CIFAR-10/100ではプレアクティベーションモデルは基準モデルより一貫して上回った(例:ResNet-1001 CIFAR-10:4.92% 基準 vs 4.89% ±0.14、CIFAR-100:22.71% vs 22.68% ±0.22)。
- ImageNetでは、同等アーキテクチャでプレアクティベーションResNetは元の設計よりも改善を示した:ResNet-152 top-1 21.1% vs 21.3%(標準設計)、プレアクティベーションを用いたResNet-200は 20.7% top-1(320x320 テスト)に対し元は 21.8%。スケールやアスペクト拡張を加えるとプレアクティベーションResNet-200は 20.1% top-1(スケール+アスペクト拡張)および 4.8% top-5 に達する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。