[論文レビュー] Impression Network for Video Object Detection
本稿では、希釈されたキーフレームから高レベルの特徴を伝搬することで低品質なフレームを向上させる反復的インプレッション特徴集約メカニズムを用いた、新しい特徴レベルの動画オブジェクト検出フレームワーク、Impression Networkを提案する。長距離のセグメントにわたり最小限の計算コストで特徴を統合することで、20 fpsの推論速度を達成し、ImageNet VIDでフレーム単位のベースラインを上回る精度を実現し、効率的で正確な動画特徴強化のための新しいパラダイムを提供する。
Video object detection is more challenging compared to image object detection. Previous works proved that applying object detector frame by frame is not only slow but also inaccurate. Visual clues get weakened by defocus and motion blur, causing failure on corresponding frames. Multi-frame feature fusion methods proved effective in improving the accuracy, but they dramatically sacrifice the speed. Feature propagation based methods proved effective in improving the speed, but they sacrifice the accuracy. So is it possible to improve speed and performance simultaneously? Inspired by how human utilize impression to recognize objects from blurry frames, we propose Impression Network that embodies a natural and efficient feature aggregation mechanism. In our framework, an impression feature is established by iteratively absorbing sparsely extracted frame features. The impression feature is propagated all the way down the video, helping enhance features of low-quality frames. This impression mechanism makes it possible to perform long-range multi-frame feature fusion among sparse keyframes with minimal overhead. It significantly improves per-frame detection baseline on ImageNet VID while being 3 times faster (20 fps). We hope Impression Network can provide a new perspective on video feature enhancement. Code will be made available.
研究の動機と目的
- 画像の劣化(ボケや運動歪みなど)が生じる状況下でも、速度と精度のトレードオフを解消すること。
- 高い計算コストを伴わずに、長距離のマルチフレーム特徴統合を効率的に行えるようにすること。
- 人間の視覚認識を模倣し、時間的インプレッションを蓄積することで、弱い視覚的手がかりを持つ低品質フレームの検出を改善すること。
- リアルタイムの推論速度を維持しながら、フレーム単位の検出ベースラインを上回ること。
- タスクに依存しない特徴レベルのフレームワークを提供し、後続の検出タスクのための動画特徴品質を向上させること。
提案手法
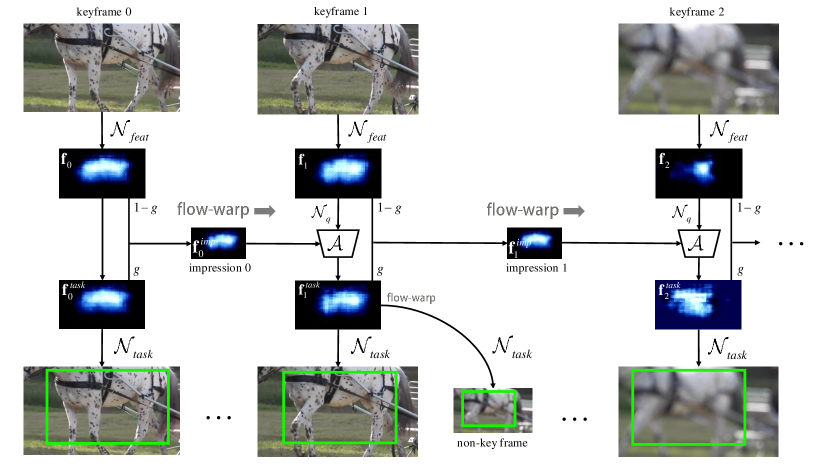
- フレームワークは動画を固定長のセグメントに分割し、各セグメントの中央に位置する1つのキーフレームを選択して、ResNet-101などのバックボーンを用いて深層特徴を抽出する。
- フローベースの特徴伝搬メカニズムにより、キーフレームの特徴を非キーフレームに再利用することで、リアルタイムの速度を維持する。
- 各新しいキーフレームからの特徴を吸収することで、インプレッション特徴が反復的に更新され、高レベルのオブジェクトの手がかりを蓄積する累積メモリとして機能する。
- 各キーフレームのタスク固有特徴は、自身の特徴と伝搬されたインプレッション特徴の重み付き組み合わせであり、劣化したフレームにおける特徴強化を可能にする。
- インプレッション特徴は再帰的集約ルールにより更新される:$ I_{t} = (1-g)I_{t-1} + g \cdot f_t $、ここで $ g $ は時間的影響範囲を制御する。
- 本手法はセグメントペアごとに1回のフローよりの推定のみを必要とし、空間的アライメントのコストを最小限に抑え、効率的な長距離統合を可能にする。
実験結果
リサーチクエスチョン
- RQ1時間的文脈を活用することで、特徴レベルの手法が動画オブジェクト検出において、高精度かつ高速な両立を達成できるか?
- RQ2推論速度を犠牲にせずに、長距離の特徴統合をどのように効率的に行えるか?
- RQ3過去の特徴の蓄積的インプレッションが、視覚的手がかりが弱い低品質フレームの検出をどの程度改善できるか?
- RQ4フローガイドド特徴伝搬誤差を最小限に抑えるために、最適なキーフレーム選択戦略は何か?
- RQ5既存の特徴集約および伝搬技術と比較して、インプレッションメカニズムは精度と効率の両面でどのように優れているか?
主な発見
- Impression Networkは20 fpsの推論速度を達成しており、これはフレーム単位のベースラインの3倍速く、検出精度を顕著に向上させた。
- FGFAのような最先端の集約ベース手法を上回り、ImageNet VIDで50msの推論時間で75.5%のmAPを達成した。
- インプレッションメカニズムにより、焦点が合っていないやぼやけたフレームの検出が向上し、図5および図1で示されたように、以前のキーフレームからの高品質な特徴を伝搬することで実現された。
- 集約重み $ g $ を1.0に設定することで、時間的文脈を完全に活用でき、最高のmAPが得られた。これは、長距離特徴統合が耐性を高めることを示している。
- 中央キーフレーム選択により、平均的特徴伝搬距離 $ \bar{d} $ が最小限に抑えられ、フローエラーが低減され、性能が向上した。これは表2で確認された。
- さまざまなセグメント長にわたり、滑らかな精度-速度トレードオフを維持しており、特に高速な領域において、フレーム単位のベースラインおよびDeep Feature Flowを上回った。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。