[論文レビュー] Improving Assessment of Tutoring Practices using Retrieval-Augmented Generation
この論文は、GPTモデルを用いたプロンプト戦略を評価し、チューターの社会・情動学習能力を自動で評価する。RAGベースのプロンプトが、特にGPT-4で、正確性(幻覚の少なさ)とコストのバランスを最適化することを示している。
One-on-one tutoring is an effective instructional method for enhancing learning, yet its efficacy hinges on tutor competencies. Novice math tutors often prioritize content-specific guidance, neglecting aspects such as social-emotional learning. Social-emotional learning promotes equity and inclusion and nurturing relationships with students, which is crucial for holistic student development. Assessing the competencies of tutors accurately and efficiently can drive the development of tailored tutor training programs. However, evaluating novice tutor ability during real-time tutoring remains challenging as it typically requires experts-in-the-loop. To address this challenge, this preliminary study aims to harness Generative Pre-trained Transformers (GPT), such as GPT-3.5 and GPT-4 models, to automatically assess tutors' ability of using social-emotional tutoring strategies. Moreover, this study also reports on the financial dimensions and considerations of employing these models in real-time and at scale for automated assessment. The current study examined four prompting strategies: two basic Zero-shot prompt strategies, Tree of Thought prompt, and Retrieval-Augmented Generator (RAG) based prompt. The results indicate that the RAG prompt demonstrated more accurate performance (assessed by the level of hallucination and correctness in the generated assessment texts) and lower financial costs than the other strategies evaluated. These findings inform the development of personalized tutor training interventions to enhance the the educational effectiveness of tutored learning.
研究の動機と目的
- 個別化トレーニングを導くために、チューターの社会・情動学習の正確な評価を動機づける。
- GPTモデルがチューターの transcripts から初心者チューターの社会・情動実践を信頼性高く評価できるかを探る。
- リアルタイム評価における正確性とコストの観点から、ゼロショット、Tree of Thought、RAGなどのプロンプト戦略を比較する。
提案手法
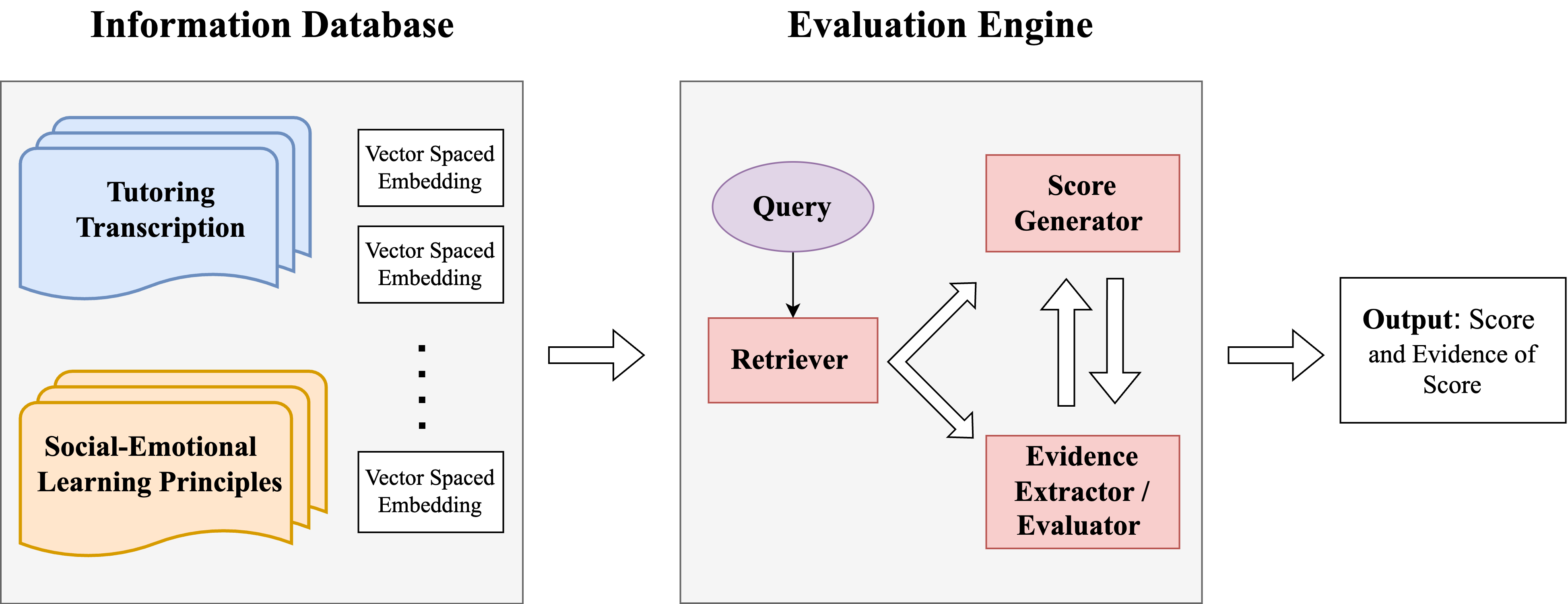
- 実世界の中学生向けチュータリング記録(Grade 6-8)を、初級チューターとのZoomセッションから使用する。
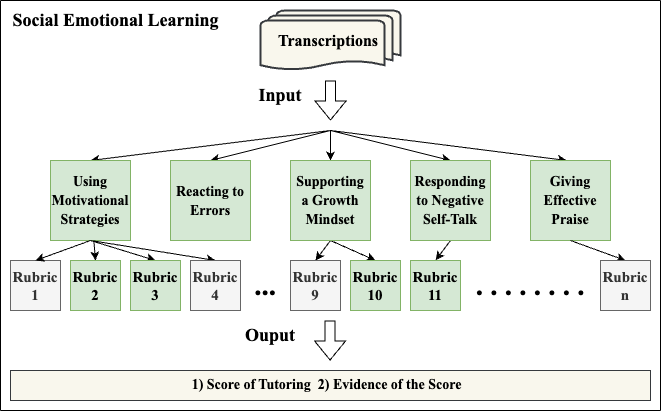
- 5つの社会・情動学習原則に基づくルーブリックを開発してチューティング実践を評価する。
- 4つの prompting戦略を設計・比較する:2つの基本的なゼロショットプロンプト、Tree of Thoughtプロンプト、Retrieval-Augmented Generator(RAG)プロンプト。
- 人間の判断と比較して、正確さと幻覚の有無をGPTの出力に注釈付けする。
- API料金を用いて、GPT-3.5 TurboとGPT-4 Turboの評価ごとのコストを算出する。
実験結果
リサーチクエスチョン
- RQ1RQ1: GPTモデルは人間のチューターの社会・情動学習能力を正確に評価できるか?
- RQ2RQ2: このタスクにおけるGPT-3.5とGPT-4の性能とコストはどのように比較されるか?
主な発見
| プロンプト | GPT-3.5 Turbo | GPT-4 Turbo |
|---|---|---|
| Zero-shot Prompt Type I | $0.100 | $1.035 |
| Zero-shot Prompt Type II | $0.014 | $0.188 |
| Tree of Thoughts (ToT) | $0.013 | $0.137 |
| Retrieval-Augmented Generation (RAG) | $0.008 | $0.137 |
- RAGプロンプティングは、他のプロンプトより幻覚が少なく、正確な評価を多く出す。
- GPT-4は一般にGPT-3.5より正確な評価を提供し、RAGとゼロショット(P1)プロンプトが最も良い性能を示す。
- RAGプロンプトはGPT-3.5とGPT-4の両方にとって最もコスト効果の高い評価戦略を提供する。
- GPT-3.5には時折幻覚が見られた(例:ネガティブな自己対話への反応の誤認識など)。
- GPT-4の結果は、プロンプト戦略全体を通じて人間の判断との整合性がより高いことを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。