[論文レビュー] Improving Factuality and Reasoning in Language Models through Multiagent Debate
本論文は、複数のLLMインスタンスが複数ラウンドにわたり回答を生成・批評・討論する多-agentディベート枠組みを提案し、推論と事実性を向上させる。単一モデルのベースラインと比較して、推論と事実性タスクで顕著な向上を達成する。
Large language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their performance may be further improved through the tools of prompting, ranging from verification, self-consistency, or intermediate scratchpads. In this paper, we present a complementary approach to improve language responses where multiple language model instances propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a common final answer. Our findings indicate that this approach significantly enhances mathematical and strategic reasoning across a number of tasks. We also demonstrate that our approach improves the factual validity of generated content, reducing fallacious answers and hallucinations that contemporary models are prone to. Our approach may be directly applied to existing black-box models and uses identical procedure and prompts for all tasks we investigate. Overall, our findings suggest that such "society of minds" approach has the potential to significantly advance the capabilities of LLMs and pave the way for further breakthroughs in language generation and understanding.
研究の動機と目的
- Motivate: 大型言語モデル(LLMs)の幻覚や推論エラーに対処する動機付け。
- Propose: 複数のLLMインスタンスが互いの解を生成・批評する多-agentディベート枠組みを提案。
- Demonstrate: ブラックボックスモデルアクセスのみを用いて、様々なタスクで推論と事実性の向上を示す。
提案手法
- 同一または混在する複数のLLMエージェントを特定のタスクに対して実装する。
- 各エージェントが独立して候補解を生成する。
- エージェントは他者の回答を読み批評し、複数ラウンドを繰り返してコンセンサスへと収束させる。
- ディベートの長さとエージェントの頑固さを制御するプロンプトを使用して収束を影響させる。
- 他のプロンプティング手法と直交性を示し、チェーン・オブ・ソウト(思考の連鎖)プロンプティングと組み合わせる。
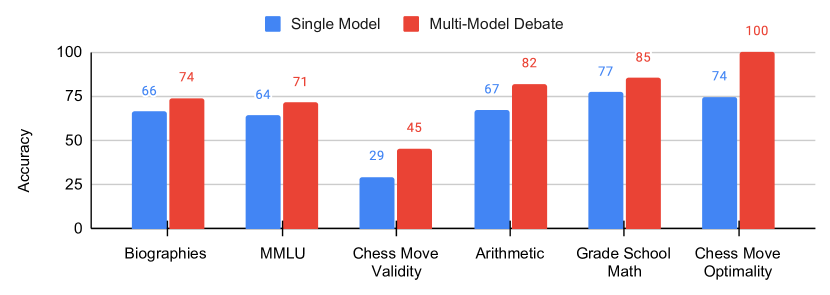
実験結果
リサーチクエスチョン
- RQ1マルチエージェント・ディベートは単一エージェントのベースラインと比較して推論パフォーマンスを改善するか。
- RQ2ディベート枠組みは多様なタスクで事実性と幻覚の低減を改善するか。
- RQ3性能を最適化する設計選択(エージェント数、ラウンド数、プロンプト)は何か。
- RQ4他のプロンプティング戦略やモデルタイプと互換性はあるか。
- RQ5個々のエージェントが不確実または誤っている場合でも、方法はロバストなコンセンサスを生成できるか。
主な発見
| Model | Arithmetic (%) ↑ | Grade School Math (%) ↑ | Chess (Δ PS) ↑ |
|---|---|---|---|
| 単一エージェント | 67.0 ± 4.7 | 77.0 ± 4.2 | 91.4 ± 10.6 |
| 単一エージェント(リフレクション) | 72.1 ± 4.5 | 75.0 ± 4.3 | 102.1 ± 11.9 |
| マルチエージェント(多数決) | 69.0 ± 4.6 | 81.0 ± 3.9 | 102.2 ± 6.2 |
| マルチエージェント(ディベート) | 81.8 ± 2.3 | 85.0 ± 3.5 | 122.9 ± 7.6 |
- マルチエージェント・ディベートは、単一エージェントのベースラインおよびリフレクションに対して、算数、GSM8K、チェスの手番予測で推論を大幅に改善する。 (算数: 81.8±2.3; GSM8K: 85.0±3.5; チェス: 122.9±7.6、ΔPS指標でディベート対ベースライン)
- ディベートは伝記、MMLU、チェスの妥当性タスクでも事実性を高め、リフレクションおよび単一エージェント手法を上回る。 (伝記: 73.8±2.3; MMLU: 71.1±4.6; チェス妥当性: 45.2±2.9)
- エージェント数とディベート回数を増やすと一般的に性能が向上するが、一定点を超えるとリターンが低下する。
- 長いディベートプロンプトは収束を遅くするが、より高品質なコンセンサスを得られる場合がある。
- 初期化プロンプト(エージェントのペルソナ)を変えると、特定のタスクでさらなる利得を生む可能性がある。
- ディベートは初期の回答が不正確でもコンセンサスへ収束させることが可能で、不確かな事実の含有を減らせる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。