[論文レビュー] Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback
本論文は、複数の大規模言語モデルが自己対話、批評モデルからのAIフィードバック、文脈内学習を通じて交渉戦略を自律的に改善できるかを検証し、一部のモデルはラウンドごとに継続的に改善する一方で他は失敗することを示している。
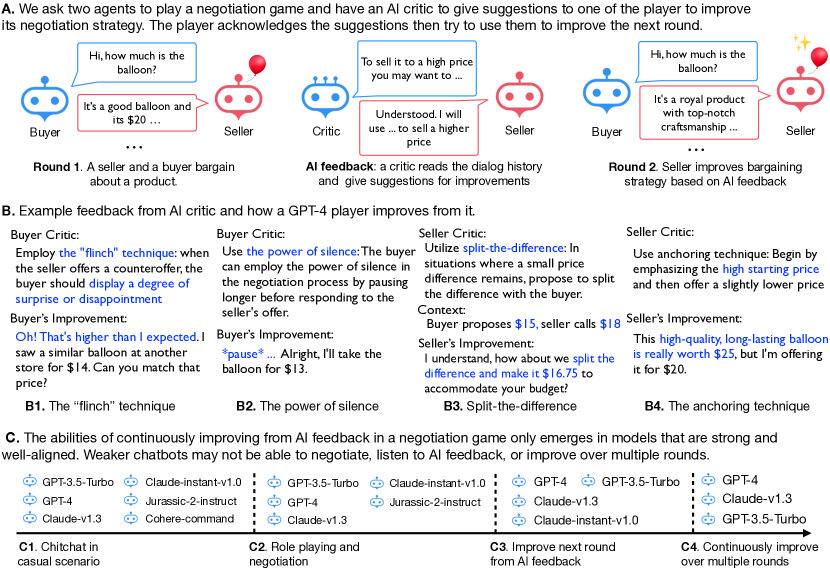
We study whether multiple large language models (LLMs) can autonomously improve each other in a negotiation game by playing, reflecting, and criticizing. We are interested in this question because if LLMs were able to improve each other, it would imply the possibility of creating strong AI agents with minimal human intervention. We ask two LLMs to negotiate with each other, playing the roles of a buyer and a seller, respectively. They aim to reach a deal with the buyer targeting a lower price and the seller a higher one. A third language model, playing the critic, provides feedback to a player to improve the player's negotiation strategies. We let the two agents play multiple rounds, using previous negotiation history and AI feedback as in-context demonstrations to improve the model's negotiation strategy iteratively. We use different LLMs (GPT and Claude) for different roles and use the deal price as the evaluation metric. Our experiments reveal multiple intriguing findings: (1) Only a subset of the language models we consider can self-play and improve the deal price from AI feedback, weaker models either do not understand the game's rules or cannot incorporate AI feedback for further improvement. (2) Models' abilities to learn from the feedback differ when playing different roles. For example, it is harder for Claude-instant to improve as the buyer than as the seller. (3) When unrolling the game to multiple rounds, stronger agents can consistently improve their performance by meaningfully using previous experiences and iterative AI feedback, yet have a higher risk of breaking the deal. We hope our work provides insightful initial explorations of having models autonomously improve each other with game playing and AI feedback.
研究の動機と目的
- 言語モデルがゲームプレイとAIフィードバックを通じて最小限の人間介入で自律的に改善する可能性を動機づける。
- 買い手と売り手が価格を交渉する設定を調査し、第三のLLMが各ラウンド後に対象プレイヤーを改善するフィードバックを提供する。
- 異なるLLMがAIフィードバックにどのように反応し、複数ラウンドで改善できるかを評価する。
- 反復ラウンドでの取引価格の高さと取引成立の可能性とのトレードオフを検討する。
提案手法
- 定義された価格目標を持つ買い手-売り手の bargaining game を2つの LLM がプレイする(買い手は低い価格を、売り手は高い価格を目指す)。
- 3番目の LLM が審判役となり、各ラウンドごとに対象プレイヤーを改善する自然言語のフィードバックを提供する。
- 前回の交渉履歴とAIフィードバックを次のラウンドのデモンストレーションとして組み込むことで文脈内学習を利用する(ICL-AIF)。
- gpt-3.5-turbo をベース競合として、複数のエンジン組み合わせ(GPTおよび Claude ファミリー)をテストする。取引価格が評価指標となる。
- モデレーターモデルがゲーム状態を分類(ON-GOING、DEAL、NO DEAL)してラウンドを管理する。
- 1ラウンドのベースライン、複数ラウンドの改善、最大5ラウンドまでの継続的改善を含む実験を実施する。
実験結果
リサーチクエスチョン
- RQ1複数のLLMが自己対話とAIフィードバックを介して交渉ゲームを自律的に互いを改善できるか?
- RQ2どのモデルが交渉の規則を理解し、AIフィードバックに応答して複数ラウンドで改善できるか?
- RQ3買い手の役割は売り手の役割より改善を難しくするのか、モデルごとにどう変わるか?
- RQ4反復ラウンドでより高い取引価格を達成することと取引成立の可能性とのトレードオフは何か?
主な発見
| GPT-3.5-Turbo | Claude-instant-v1.0 | Claude-v1.3 | |
|---|---|---|---|
| フィードバック前 | 16.26 | 14.74 | 15.40 |
| ランダムに抽出された人間のフィードバック | 16.83 (+0.57) | 16.33 (+1.59) | 16.89 (+1.58) |
| AIフィードバック | 17.03 (+0.77) | 15.98 (+1.24) | 16.98 (+1.58) |
- テスト対象のモデルの一部(例:gpt-3.5-turbo, gpt-4, claude-v1.3)は、ラウンドを跨いだAIフィードバックから継続的に改善できる。
- 買い手の役割は、いくつかのモデルにとって売り手の役割より改善が難しいことが多い;ただし、GPT-4やclaude-v1.3のようなモデルは買い手として改善できる場合もあり、他はできない。
- より強力なエージェントは過去の経験とAIフィードバックを活用して複数ラウンドで改善できるが、高めの価格は取引成立のリスクを高める。
- AIフィードバックは人間のフィードバックと同等の改善を生み出す可能性があり、交渉戦略を導くのによりスケーラブルである。
- 複数ラウンド設定では、学習に伴い冗長性が増すことがあるが、戦略的品質(長さだけでなく)によって取引結果が向上する。
- 研究はAIフィードバックから学習する際の取引の質と信頼性のトレードオフを強調する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。