[論文レビュー] Improving Multimodal Datasets with Image Captioning
本論文は、画像キャプション生成モデルによって作成された合成キャプションをウェブ収集の画像-テキストデータに追加することで、CLIPの学習を改善し、小規模および中規模で強力な生データフィルタリングのベースラインを上回り、キャプションの品質・多様性・スケーリング効果に関する洞察を提供する。
Massive web datasets play a key role in the success of large vision-language models like CLIP and Flamingo. However, the raw web data is noisy, and existing filtering methods to reduce noise often come at the expense of data diversity. Our work focuses on caption quality as one major source of noise, and studies how generated captions can increase the utility of web-scraped datapoints with nondescript text. Through exploring different mixing strategies for raw and generated captions, we outperform the best filtering method proposed by the DataComp benchmark by 2% on ImageNet and 4% on average across 38 tasks, given a candidate pool of 128M image-text pairs. Our best approach is also 2x better at Flickr and MS-COCO retrieval. We then analyze what makes synthetic captions an effective source of text supervision. In experimenting with different image captioning models, we also demonstrate that the performance of a model on standard image captioning benchmarks (e.g., NoCaps CIDEr) is not a reliable indicator of the utility of the captions it generates for multimodal training. Finally, our experiments with using generated captions at DataComp's large scale (1.28B image-text pairs) offer insights into the limitations of synthetic text, as well as the importance of image curation with increasing training data quantity. The synthetic captions used in our experiments are now available on HuggingFace.
研究の動機と目的
- キャプションの品質に焦点を当てることで、ノイズのあるウェブ規模の画像-テキストデータセットの改善を動機づける。
- BLIP2 などのモデルによる合成キャプションがマルチモーダル事前学習に与える影響を評価する。
- 生データと合成キャプションの混合戦略と従来のフィルタリングを比較する。
- ノイズ・多様性・画像-テキストの整合性といったキャプション品質要因を分析して、性能向上の理由を説明する。
提案手法
- BLIP、BLIP2、OpenCLIP-CoCa などのキャプション生成モデルを用いて、ウェブ収集済みの画像-テキスト対に top-K サンプリングで合成キャプションを生成する。
- 小・中・大の候補プール(12.8M、128M、1.28B)を対象に、合成キャプションを追加した画像-テキスト対で CLIP モデルを訓練する。
- ゼロショットの ImageNet、38タスクの平均精度、Flickr30K および MS-COCO での検索を評価する。
- MS-COCO でのファインチューニングの有無によるキャプション生成モデルを比較し、下流の CLIP 性能への影響を評価する。
- ノーフィルタリング、CLIPスコアフィルタリング、コサイン類似度閾値の下で生データと合成キャプションを混合する戦略を含むデータ混合戦略を実験する。

実験結果
リサーチクエスチョン
- RQ1生データのウェブデータのみをフィルタリングする場合と比べて、合成キャプション化は CLIP の学習を改善するか?
- RQ2異なるキャプション生成モデルとその学習(ファインチューニングあり/なし)がマルチモーダル学習の有効性にどう影響するか?
- RQ3生データと合成キャプションの混合戦略のうち、どの戦略が性能を最大化し、データ規模とともにどう変化するか?
- RQ4キャプションの属性(ノイズ、多様性、整合性)が下流タスクの改善をどう促すか?
- RQ5合成キャプションの利点は、小規模から超大規模データプールへとどう拡大するか?
主な発見
| 手法 | 平均検索結果 (MS-COCO & Flickr) |
|---|---|
| Raw (no filtering) | 13.2 |
| Raw (top 30% intersect IN1k) | 18.2 |
| Raw (top 30%) | 19.7 |
| Raw (top 30%) + BLIP2 (70%, filtered) | 38.0 |
| BLIP2 (top 75% intersect IN1k) | 38.9 |
| BLIP2 (top 50%) | 40.1 |
| Raw (top 30%) + BLIP2 (70%) | 40.5 |
| BLIP2 (no filtering) | 41.7 |
- キャプション生成モデルのうちキャプション生成目的でファインチューニングされていないものは、テキストの多様性が高いため、ImageNetと検索の全体的な CLIP 性能が、ファインチューニング済みのキャプショナーより良くなる傾向がある。
- 合成キャプションは一般に生データのキャプションより画像-テキストの整合性が高く(ノイズが低い)一方で生データは多様性が高い。両方を類似性閾値の下で組み合わせるとより良い結果になる。
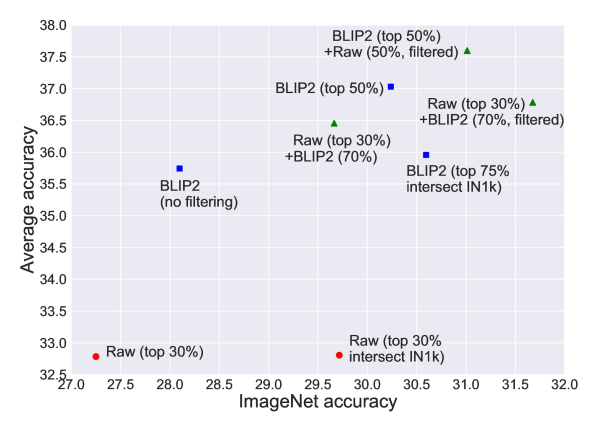
- 中規模(128M)では、生データと合成キャプションをコサイン閾値で混合すると、ImageNetと38タスクの平均性能が、最高の生データベースのベースラインを ImageNetで約2%、タスク全体で平均約4%上回る。
- BLIP2 生成キャプションは、生データキャプションのみを使用した場合と比べて Flickr および MS-COCO の検索を大幅に向上させる(2倍超)。
- 大規模(400M–1.28B)では、画像-contentのキュレーションとテキスト多様性に対処しないと ImageNet の利得は低下するが、合成キャプションによる検索の利得は規模に関係なく持続する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。