[論文レビュー] Improving Retrieval for RAG based Question Answering Models on Financial Documents
この論文は金融文書に対する標準的なRAGパイプラインの制限を分析し、検索品質を向上させる技術を提案する。高度なチャンク化、クエリ拡張(HyDE)、メタデータ注釈、リランキング、埋め込みのファインチューニングを含む。
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
研究の動機と目的
- 現在のRAGパイプラインがドメイン特化(金融)QAタスクで抱える限界を特定する。
- 文脈品質と回答の正確性を向上させる検索強化を提案・評価する。
- 金融に焦点を当てたQ&Aで幻覚を軽減し、信頼性を向上させる技術を実証する。
提案手法
- RAGパイプラインにおける均一チャンク化とコサイン類似度ベースの検索の限界を批判的に検討する。
- 見出しや表などのドキュメント構造に基づき再帰的に分割する適応的チャンク化戦略を提案する。
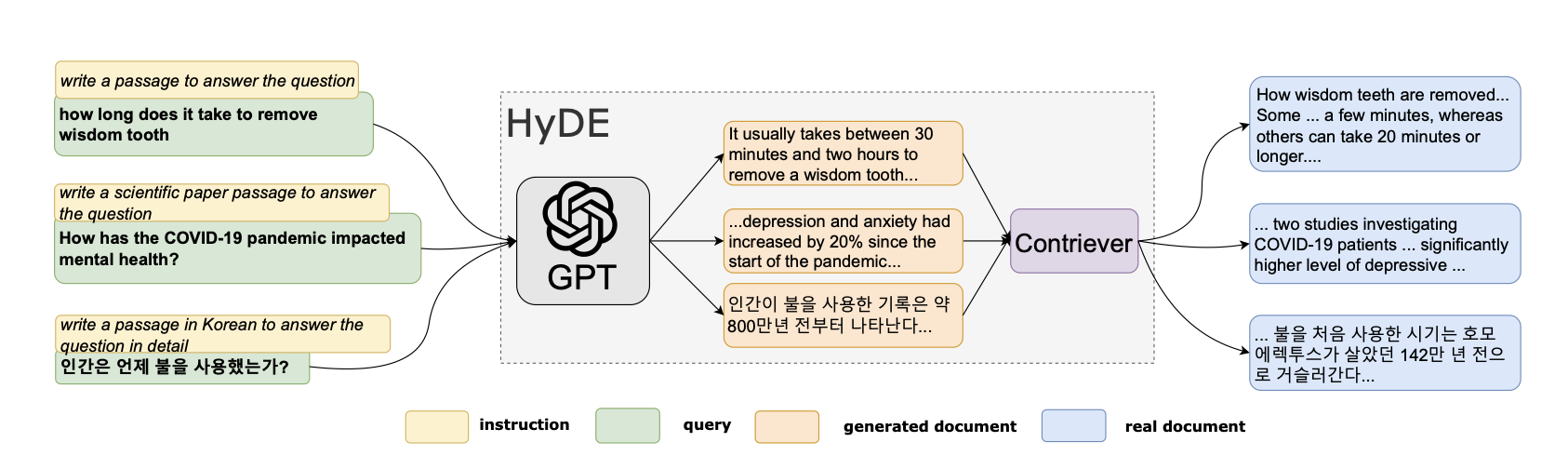
- Hypothetical Document Embeddings (HyDE)を用いたクエリ拡張を検討し、検索ガイダンスを向上させる。
- ドキュメントの識別性と文脈を保持するためのメタデータ注釈とドキュメント別インデックス付けを導入する。
- 真に関連性の高いチャンクを単なる類似性より優先するリランキングアルゴリズムを適用する。
- 金融用語とニュアンスを捉えるため、ドメイン特有のデータで埋め込みをファインチューニングすることを提案する。
実験結果
リサーチクエスチョン
- RQ1現在のRAGパイプラインは複数文書にまたがる金融Q&Aタスクにどのように不適合か。
- RQ2チャンク化、HyDE、メタデータ、リランキング、ドメイン特有の埋め込みなどの改善された検索戦略は、金融文書における回答の品質と信頼性を高められるか。
- RQ3構造化された金融データセットにおいて、検索品質と回答の忠実性を最も適切に評価する評価戦略は何か。
主な発見
- 均一なチャンク化を超え、文書構造を意識したチャンク化へ移行することで、検索品質と回答の忠実性を向上させられる。
- HyDEスタイルのクエリ拡張は、ユーザーの元の質問を超えた文脈の特定を助け、検索エラーを減らす。
- メタデータ注釈はドキュメント間の混乱を減らし、複数文書にまたがる文脈の保持を改善する。
- リランキングは単なる類似性より文脈の関連性を優先させ、取得チャンクの品質を向上させる。
- ドメインデータでの埋め込みファインチューニングは、金融特有の文脈での検索を向上させる。
- FinanceBench (10-K, 10-Q, 8-K, earnings reports) は、検索とQA性能の構造化評価のグラウンドトゥルースを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。