[論文レビュー] Improving Text Embeddings with Large Language Models
著者は独自の大規模言語モデルを用いて多様な合成データを生成し、オープンソースのデコーダー専用モデルをテキスト埋め込みの訓練に用い、1k未満の訓練ステップかつラベルデータなしで強い結果を達成し、合成データと少量のラベルデータを併用した場合 BEIR と MTEB で最先端を達成。
In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across 93 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.
研究の動機と目的
- テキスト埋め込みを、多段階のパイプラインや大規模なラベル付きデータセットを使わずに改善する動機づけ。
- 多言語・多タスクにわたるLLMを用いたシンプルな合成データ生成パイプラインを提案。
- 合成データでオープンソースLLMを微調整すると埋め込みが競争力を持つことを実証。
- ラベル付きデータを含む場合にBEIRとMTEBで最先端の結果を示す。
- アプローチの多言語対応と長文コンテキスト能力について議論。
提案手法
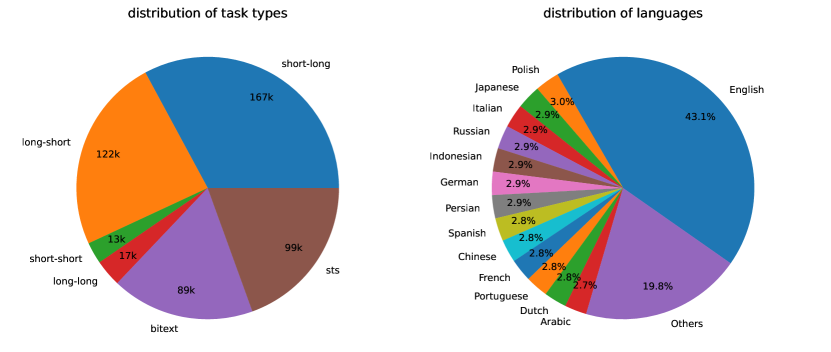
- 93言語にわたるタスク特異的な合成(クエリ、ポジティブ、ハードネガティブ)トリップレットをブレインストーミングし生成するために独自LLMsを使用。
- 2段階のプロンプト戦略を適用:タスクプールをブレインストームし、次にタスク定義に条件付けてデータを生成。
- オープンソースのデコーダー専用LLM(Mistral-7B)を、Syntheticデータ(そして利用可能なMS MARCO)上でInfoNCEコントラスト損失で微調整。
- プレtrained LLMの最後のトークン埋め込みをクエリ/文書表現として使用し、コサイン類似度の温度τ=0.02を適用。
- LoRAをランク16で採用し、勾配チェックポイント、混合精度、DeepSpeed ZeRO-3などのトレーニング工夫を導入して<1kステップを実現。
- RoPE回転ベースの調整や合成長文タスクを用いて長文コンテキスト能力を探索。

実験結果
リサーチクエスチョン
- RQ1LLMが生成した合成データを用いた単段階訓練で高品質なテキスト埋め込みを学習できるか?
- RQ2合成データだけと合成データ plus ラベル付きデータのベンチマーク性能(BEIR, MTEB)への影響は?
- RQ3多言語カバレッジが高資源言語と低資源言語の埋め込み品質にどう影響するか?
- RQ4高度に事前学習されたLLMにとって、良い埋め込みを得るためにコントラスト事前学習は必須か?
- RQ5埋め込みを長文コンテキストタスクや個別化リトリーブシナリオへ拡張できるか?
主な発見
| データセット数 | 分類 | クラスタ | ペア分類 | リランク | 検索 | STS | 要約 | 平均 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 56 | 12 | 11 | 3 | 4 | 15 | 10 | 1 | 66.6 | ||
| 56 | Unsupervised Models | Glove | 57.3 | 27.7 | 70.9 | 43.3 | 21.6 | 61.9 | 28.9 | 42.0 |
| 56 | SimCSE bert-unsup | 62.5 | 29.0 | 70.3 | 46.5 | 20.3 | 74.3 | 31.2 | 45.5 | |
| 56 | Supervised Models | SimCSE bert-sup | 67.3 | 33.4 | 73.7 | 47.5 | 21.8 | 79.1 | 23.3 | 48.7 |
| 56 | Contriever | 66.7 | 41.1 | 82.5 | 53.1 | 41.9 | 76.5 | 30.4 | 56.0 | |
| 56 | GTR xxl | 67.4 | 42.4 | 86.1 | 56.7 | 48.5 | 78.4 | 30.6 | 59.0 | |
| 56 | Sentence-T5 xxl | 73.4 | 43.7 | 85.1 | 56.4 | 42.2 | 82.6 | 30.1 | 59.5 | |
| 56 | E5 large-v2 | 75.2 | 44.5 | 86.0 | 56.6 | 50.6 | 82.1 | 30.2 | 62.3 | |
| 56 | GTE large | 73.3 | 46.8 | 85.0 | 59.1 | 52.2 | 83.4 | 31.7 | 63.1 | |
| 56 | BGE large-en-v1.5 | 76.0 | 46.1 | 87.1 | 60.0 | 54.3 | 83.1 | 31.6 | 64.2 | |
| 56 | Ours E5 mistral-7b full data | 78.5 | 50.3 | 88.3 | 60.2 | 56.9 | 84.6 | 31.4 | 66.6 | |
| 56 | Ours w/ synthetic data only | 78.2 | 50.5 | 86.0 | 59.0 | 46.9 | 81.2 | 31.9 | 63.1 | |
| 56 | Ours w/ synthetic + msmarco | 78.3 | 49.9 | 87.1 | 59.5 | 52.2 | 81.2 | 32.7 | 64.5 |
- 合成データのみでトレーニングしても、ラベルデータなしでMTEBの性能で競争力を示す。
- 合成データとラベルデータの混合で微調整すると、BEIRとMTEBベンチマークで最先端の結果を実現。
- 合成データのみのモデルは平均MTEBスコア63.1に到達し、Synthetic + MS-MARCOは64.5、全データは66.6に到達。
- E5_mistral-7bは全データでMTEB平均を用いた従来の最先端を2.4ポイント上回る。
- コントラスト事前訓練はMistral-7Bベースのモデルでは他のアーキテクチャより影響が小さく、自己回帰型事前訓練が強力な表現を提供することを示唆。
- このアプローチは93言語へスケールし、長文コンテキスト能力をコンテキスト長の拡張を通じて示し、資源豊富言語で最良の結果を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。